Contributors: Chen Wang, Shiquan Su and Anoop Madhusoodhanan Prabha
Introduction
SYCL* C++ programing standard is royalty-free, template based, cross-platform abstraction, targeting heterogeneous computing architecture with a host connected to various type of accelerators, typically GPU, CPU and FPGA. The SYCL* standard evolves substantially from the previous version SYCL 1.2 to the current version, SYCL* 2020 (rev. 5). In the newer SYCL* 2020, the OpenCL* is separated from SYCL* as an individual backend candidate. Compared to SYCL* 1.2, which solely relies on OpenCL* Standard to operate the accelerators, the latest SYCL* 2020 works independently from OpenCL*, and can target various low-level APIs, implemented under the concept of “backend”. Some of the popular low-level APIs are OpenCL*, CUDA, Level0, HIP, XRT, Vulkan, etc.
The abstraction on the top of low-level API allows SYCL* programmer incrementally build up SYCL* application by consuming kernels developed by various backends. Consuming kernel from other programming framework in SYCL* is a lesser known but powerful feature, which is referred as interoperability. The SYCL* programming model open up a promising path to let the stakeholders to break the chains of proprietary lock-in, so the stakeholders can fully control the budget allocation, diversify the technical roadmap, and unleash the full potential of the hardware investment. Moreover, the SYCL* programming model allows the migration from other hardware specified code base to SYCL* to be incremental, which is pivotal to modern fast pace Continuous Integration/Continuous Deployment workflows. One of the vehicles enabling the incremental migration is interoperability. Interoperability allows the SYCL* code to reuse the existing source codes, objects, and executables/kernels from various backends.
A common example of SYCL* interoperability has been demonstrated below. The example under the SYCL* 1.2.1 specification has been shown first, so it can be connected to many existing publications and online content. Then, the updated approach under SYCL* 2020 specification is shown. In the example, the main code in SYCL* digests a piece of existing kernel source code written in OpenCL*. The SYCL* code will generate a SYCL* kernel based on the input OpenCL* kernel, then enqueue the SYCL* kernel result in the SYCL* queue. It is implementation dependent that how each backend handles the kernel generation.
The general steps of SYCL*-OpenCL* interoperation steps are:
- As common in SYCL* code, calling SYCL* device selector defines the SYCL* device. Then, the SYCL* context is formed by the SYCL* device.
- Then, the next layer is programmed and queued. The queue is defined by the device. Meanwhile, the program is defined by the context, then built with the OpenCL* source code.
- The SYCL* code constructs the data_buffer object and the SYCL* queue submission provides the handler, then the SYCL* code constructs the accessor by both the data_buffer and handler. The SYCL* compiler has no visibility inside the backend OpenCL* kernel, so the kernel arguments must explicitly be passed into the Backend kernel executable by the set_args() interface.
- Finally, the handler method parallel_for<>() can run backend OpenCL* kernel executable in the SYCL* queue.
SYCL* 1.2.1 Implementation
Before the release of SYCL* 2020 specification, there were existing examples online demonstrating the interoperability. The main tool in these early examples is the “program” class, the program class object consumes the OpenCL* kernel source code, then builds the OpenCL* source code into kernel executable. The SYCL* queue can enqueue the generated kernel executable. After this magic step, the SYCL* queue can access the SYCL* runnable kernel from the OpenCL* “program” object.
#include <CL/sycl.hpp>
#include <iostream>
using namespace sycl;
int main() {
constexpr size_t size = 16;
std::array<int, size> data;
for (int i = 0; i < size; i++) data[i] = i;
buffer data_buf{ data };
// BEGIN CODE SNIP 1
queue Q{ cpu_selector{} };
cl::sycl::context sc = Q.get_context();
//SYCL Kernel built with OpenCL C kernel source
cl::sycl::program p{ Q.get_context() };
p.build_with_source(R"CLC(kernel void add(global int *data){
int index=get_global_id(0);
data[index]=data[index]+1;
})CLC", "-cl-fast-relaxed-math");
std::cout << "Running on device: " << Q.get_device().get_info<info::device::name>() << "\n";
Q.submit([&](handler& h) {
accessor data_acc{ data_buf,h };
h.set_args(data_acc);
h.parallel_for(size, p.get_kernel("add"));
});
Q.wait();
for (int i = 0; i < size; i++) {
if (data[i] != i + 1) { std::cout << "Results did not validate at index " << i << "!\n"; return -1; }
}
std::cout << "Success! Running SYCL Kernel built with OpenCL C kernel source\n";
// BEGIN CODE SNIP 2
const char* kernelSource = R"CLC(kernel void add(global int* data) {
int index = get_global_id(0);
data[index] = data[index] + 1;
})CLC";
for (int i = 0; i < size; i++) data[i] = i;
buffer data_buf2{ data };
queue Q2{ cpu_selector{} };
cl::sycl::context sc2 = Q2.get_context();
cl_context c2 = sc2.get();
//SYCL Kernel built with OpenCL C kernel objects
cl_program p2 = clCreateProgramWithSource(c2, 1, &kernelSource, nullptr, nullptr);
clBuildProgram(p2, 0, nullptr, nullptr, nullptr, nullptr);
cl_kernel k2 = clCreateKernel(p2, "add", nullptr);
std::cout << "Running on device: " << Q2.get_device().get_info<info::device::name>() << "\n";
Q2.submit([&](handler& h2) {
accessor data_acc2{ data_buf2, h2 };
h2.set_args(data_acc2);
h2.parallel_for(size, kernel{ k2, sc2 });
});
clReleaseContext(c2);
clReleaseProgram(p2);
clReleaseKernel(k2);
Q2.wait();
for (int i = 0; i < size; i++) {
if (data[i] != i + 1) { std::cout << "Results did not validate at index " << i << "!\n"; return -1; }
}
std::cout << "Success! Running SYCL Kernel built with OpenCL C kernel objects\n";
return 0;
}
The key step is including the compiler parameter “D__SYCL_INTERNAL_API” of macro definition to bring in the macro which defines the “program” class in cl::sycl class. The compiled line command shows below:
dpcpp test-sycl_opencl-program_class.cpp -D__SYCL_INTERNAL_API -lOpenCL
The “program” class in the sycl namespace is marked deprecated in SYCL* 2020, and will be removed in SYCL* 2023. In SYCL* 2020, the “program” class can only be included here by defining “__SYCL_INTERNAL_API”. Moving forward, the “program” class should come from the backend class, OpenCL* here.
SYCL* 2020 Implementation
Next, we will show how to run the same kernel under SYCL* 2020.
SYCL* application interoperates with the SYCL* backend API on SYCL* classes: buffer, context, device, device_image, event, kernel, kernel_bundle, platform, queue, sampled_image, and unsampled_image.
There are three ways the SYCL* code interoperates with the backend:
- get_native<>(): This set of template functions extracts info from object of SYCL* class to generate the object of desired backend class.
- make_{sycl_class}<>(): This set of template functions combines info from object of backcend class, such as OpenCL*, to generate the object of SYCL* class.
- interop_handle ( get_native_*<>() ) in host_task: The interop_handle class provides access to the native backend object associated with the queue, device, context and any buffers or images that are captured in the callable being invoked in order to allow a host task to be used for interoperability purposes.
Here, we combine the two ways: template function get_native<>() method and template function sycl::make_{sycl_class}<>(), to demonstrate how SYCL* 2020 and OpenCL* backend interoperate.
The following is the general workflow:
The SYCL* code calls the SYCL* get_native method to define the backend OpenCL* device and context. Then, the OpenCL* backend constructs OpenCL* command queue, buffer, program, and kernel. Finally, the SYCL* code specify the SYCL* queue, buffer, and kernel via template function sycl::make_{sycl_class}.
#include<CL/sycl.hpp>
#include<iostream>
int main() {
constexpr size_t size = 16;
std::array<int, size> data;
for (int i = 0; i < size; i++) { data[i] = i; }
sycl::device dev(sycl::cpu_selector{});
sycl::context ctx=sycl::context(dev);
auto ocl_dev=sycl::get_native<cl::sycl::backend::opencl,sycl::device>(dev);
auto ocl_ctx=sycl::get_native<cl::sycl::backend::opencl,sycl::context>(ctx);
cl_int err = CL_SUCCESS;
cl_command_queue ocl_queue = clCreateCommandQueueWithProperties(ocl_ctx, ocl_dev,0,&err);
sycl::queue q=sycl::make_queue<sycl::backend::opencl>(ocl_queue,ctx);
cl_mem ocl_buf = clCreateBuffer(ocl_ctx,CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR, size * sizeof(int), &data[0],&err);
sycl::buffer<int, 1> buffer =sycl::make_buffer<sycl::backend::opencl, int>(ocl_buf, ctx);
const char* kernelSource =
R"CLC(
kernel void add(global int* data) {
int index = get_global_id(0);
data[index] = data[index] + 1;
}
)CLC";
cl_program ocl_program = clCreateProgramWithSource(ocl_ctx,1,&kernelSource, nullptr, &err);
clBuildProgram(ocl_program, 1, &ocl_dev, nullptr, nullptr, nullptr);
cl_kernel ocl_kernel = clCreateKernel(ocl_program, "add", nullptr);
sycl::kernel add_kernel = sycl::make_kernel<sycl::backend::opencl>(ocl_kernel, ctx);
q.submit([&](sycl::handler& h){
auto data_acc =buffer.get_access<sycl::access_mode::read_write, sycl::target::device>(h);
h.set_args(data_acc);
h.parallel_for(size,add_kernel);
}).wait();
clEnqueueReadBuffer(ocl_queue, ocl_buf, CL_TRUE, 0, size*sizeof(int), &data[0], 0, NULL, NULL);
for (int i = 0; i < size; i++) {
if (data[i] != i + 1) { std::cout << "Results did not validate at index " << i << "!\n"; return -1; }
}
std::cout << "Success!\n";
return 0;
}
In the above code, we used sycl::cpu_selector{} to create a CPU device, also if sycl::default_selector{}is used to create a default device, and then environment variable SYCL_DEVICE_FILTER is used to control the code running on CPU or GPU or FPGA. For example, setting SYCL_DEVICE_FILTER=OPENCL:CPU, the code will run on CPU. Setting SYCL_DEVICE_FILTER=OPENCL:GPU, the code will run on GPU.
SYCL* 2020 kernel_bundle Discussion
In SYCL* 2020, since the “program” class is moved to backend, SYCL* has a new class “kernel_bundle”. The idea is that SYCL* implements the interoperability through bundling the backend kernels into the SYCL* code. SYCL* 2020 defines a kernel bundle as a layer of abstraction on top of individual kernel, which bundle a set of kernels that is defined by the same context and can be executed on different devices, where each device is in the same context. A kernel bundle includes all SYCL* kernel functions in the SYCL* application, or a part of it.
The kernel bundles provide an extension point to interoperate with backend and device specific features. Some examples of this include, invocation of device specific built-in kernels, online compilation (also known as “Just-In-Time” compilation) of kernel code with vendor specific options, or interoperation with kernels created with backend APIs.
The kernel_bundle process has enhanced features that allow the SYCL* code bundles the backend kernel in different states. There are 3 states: Input, Object, and Executable state.
The kernel inside the kernel bundle is identified by kernel_id. The template function to obtain the kernel_id is get_kernel_ids<>().
From backend, OpenCL* class cl_program object, the template function sycl::make_kernel_bundle<>() generates a sycl::kernel_bundle.
Then, the kernel invocation command, such as parallel_for, can enqueue the SYCL* kernel from a sycl::kernel_bundle identified by the kernel_id.
Currently, sycl::make_kernel_bundle<>() and get_kernel_ids<>() are not fully working yet.
The make_kernel_bundle command to bundle a kernel looks like:
auto mybundle = sycl::make_kernel_bundle<sycl::backend::opencl, sycl::bundle_state::executable>(ocl_program, ctx);
Currently, this command does not work properly, the kernel_id in mybundle is a null vector.
The feature request and development update are documented in the Khronos Group Gitlab issue 568:
https://gitlab.khronos.org/sycl/Specification/-/issues/568
SYCL* 2020 – OpenCL* Interoperability Summary
Finally, we summarize some useful SYCL* 2020 – OpenCL* interoperability in the following figure:
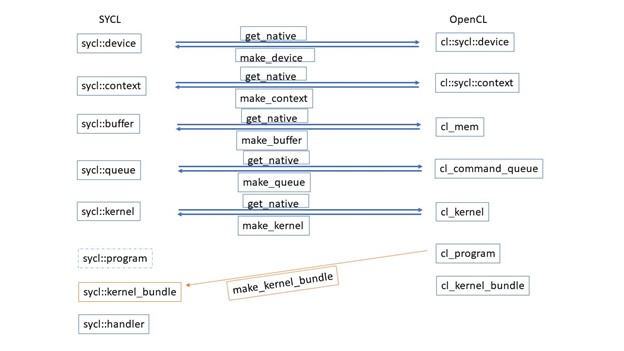
The sycl::program will be removed. The sycl::kernel_bundle and make_kernel_bundle<>() are still under development.
The SYCL* 2020 – OpenCL* interoperability can be demonstrated in the single kernel example in the previous section.