Seekr Grows AI Business with Big Cost Savings on Intel® Tiber™ Developer Cloud
April 10, 2024 | Intel® Tiber® Developer Cloud
Trustworthy AI for content evaluation and generation at reduced costs
![]() Named one of the most innovative companies of 2024 by Fast Company, Seekr is using the Intel® Tiber™ Developer Cloud1 to build, train, and deploy advanced LLMs on cost-effective clusters running on the latest Intel hardware and software, including Intel® Gaudi® 2 AI accelerators. This strategic collaboration to accelerate AI helps Seekr meet the enormous demand for compute capacity while reducing its cloud costs and increasing workload performance.
Named one of the most innovative companies of 2024 by Fast Company, Seekr is using the Intel® Tiber™ Developer Cloud1 to build, train, and deploy advanced LLMs on cost-effective clusters running on the latest Intel hardware and software, including Intel® Gaudi® 2 AI accelerators. This strategic collaboration to accelerate AI helps Seekr meet the enormous demand for compute capacity while reducing its cloud costs and increasing workload performance.
Solution overview at a glance
Two of Seekr’s popular products, Flow and Align, help customers leverage AI to deploy and optimize their content and advertising strategies and to train, build, and manage the entire LLM pipeline using scalable and composable workflows.
This takes immense compute capacity which, historically, would require a significant infrastructure investment and considerable cloud costs.
By moving their production workloads from on-premise to Intel Tiber Developer Cloud, Seekr is now able to employ the power and capacity of Intel hardware and software technologies—including thousands of Intel Gaudi 2 cards—to build its LLMs, and do so at a fraction of the price and with exceptionally high performance.
Read the case study (includes benchmarks)
About Seekr
Seekr builds large language models (LLMs) that identify, score, and generate reliable content at scale; the company’s goal is to make the Internet safer and more valuable to use while solving their customers’ need for brand trust. Its customers include Moderna, SimpliSafe, Babbel, Constant Contact, and Indeed.
1 Formerly “Intel® Developer Cloud”; now part of the Intel® Tiber™ portfolio of enterprise business solutions.
Intel Vision 2024 Unveils Depth & Breadth of Open, Secure, Enterprise AI
April 9, 2024
At Intel Vision 2024, Intel CEO Pat Gelsinger introduced new strategies, next-gen products and portfolios, customers, and collaborations spanning the AI continuum.
Topping the list is Intel® Tiber™, a rich portfolio of complementary business solutions to streamline deployment of enterprise software and services across AI, cloud, edge, and trust and security; and the Intel® Gaudi® 3 accelerator, bringing more performance, openness, and choice to enterprise GenAI.
More than 20 customers showcased their leading AI solutions running on Intel® architecture, with LLM/LVM platform providers Landing.ai, Roboflow, and Seekr demonstrating how they use Intel Gaudi 2 accelerators on the Intel® Tiber™ Developer Cloud to develop, fine-tune, and deploy their production-level solutions.
Specific to collaborations, Intel announced them with Google Cloud, Thales, and Cohesivity, each of whom is leveraging Intel’s confidential computing capabilities—including Intel® Trust Domain Extensions (Intel® TDX), Intel® Software Guard Extensions (Intel® SGX), and Intel® Tiber™ Trust Services1 attestation service—in their cloud instances.
A lot more was revealed, including formation of the Open Platform for Enterprise AI and Intel’s expanded AI roadmap inclusive of 6th Gen Intel® Xeon® processors with E- and P-cores and silicon for client, edge, and connectivity.
“We’re seeing incredible customer momentum and demonstrating how Intel’s open, scalable systems, powered by Intel Gaudi, Xeon, Core Ultra processors, Ethernet-enabled networking, and open software, unleash AI today and tomorrow, bringing AI everywhere for enterprises.”
Highlights
![]() Intel Tiber portfolio of business solutions simplifies the deployment of enterprise software and services, including for AI, making it easier for customers to find complementary solutions that fit their needs, accelerate innovation, and unlock greater value without compromising on security, compliance, or performance. Full rollout is planned in the 3rd quarter of 2024. Explore Intel Tiber now.
Intel Tiber portfolio of business solutions simplifies the deployment of enterprise software and services, including for AI, making it easier for customers to find complementary solutions that fit their needs, accelerate innovation, and unlock greater value without compromising on security, compliance, or performance. Full rollout is planned in the 3rd quarter of 2024. Explore Intel Tiber now.
Intel Gaudi 3 AI accelerator promises 4x more compute and 1.5x increase in memory bandwidth over Gaudi 2 and is projected to outperform NVIDIA H100 by an average of 50% on inference and 60% on power efficiency for LLaMa 7B and 70B and Falcon 180B LLMs. It will be available the 2nd quarter of 2024, including in the Intel Developer Cloud.
Intel Tiber Developer Cloud’s latest release includes new hardware and services that boost compute capacity, including bare metal as a service (BMaaS) options that host large-scale clusters of Gaudi 2 accelerators and Intel® Max Series GPUs, VMs running on Gaudi 2, storage as a service (StaaS) including file storage, and Intel® Kubernetes Service for cloud-native AI workloads.
Find out how Seekr used Intel Developer Cloud to deploy a trustworthy LLM for content generation and evaluation at scale.
Confidential computing collaborations with Thales and Cohesity increase trust and security and decrease risk for enterprise customers.
- Thales, a leading global tech and security provider, announced a data security solution comprised of its own CipherTrust Data Security Platform on Google Cloud Platform for end-to-end data protection and Intel Tiber Trust Services for confidential computing and trusted cloud-independent attestation. This will give enterprises additional controls to protect data at rest, in transit, and in use.
- Cohesity, a leader in AI-powered data security and management, announced the addition of confidential computing capabilities to Cohesity Data Cloud. The solution leverages its Fort Knox cyber vault service for data-in-use encryption, in tandem with Intel SGX and Intel Tiber Trust Services to reduce the risk posed by bad actors accessing data while it’s being processed in main memory. This is critical for regulated industries such as financial services, healthcare, and government.
Explore more
- Intel’s Enterprise Software Portfolio
- Intel Tiber Developer Cloud
- Intel® Confidential Computing Solutions
- Intel TDX
- Intel SGX
1 Formerly Intel® Trust Authority
Just Released: Intel® Software Development Tools 2024.1
March 28, 2024 | Intel® Software Development Tools
Accelerate code with confidence on the world’s first SYCL 2020-conformant toolchain
The 2024.1 Intel® Software Development Tools are now available and include a major milestone for accelerated computing: Intel® oneAPI DPC++/C++ Compiler has become the first compiler to adopt the full SYCL 2020 specification.
Why is this important?
Having a SYCL 2020-conformant compiler means developers can have confidence that their code is future-proof—it’s portable and reliably performant across the diversity of existing and future-emergent architectures and hardware targets, including GPUs.
“SYCL 2020 enables productive heterogeneous computing today, providing the necessary controls to write high-performance parallel software for the complex reality of today’s software and hardware. Intel’s commitment to supporting open standards is again showcased as they become a SYCL 2020 Khronos Adopter.”
Key Benefits
- Code with Confidence & Build Faster – Optimize parallelization for higher performance and productivity in modern C++ code via the Intel oneAPI DPC++/C++ Compiler, now with full SYCL 2020 conformance; explore new multiarchitecture features across AI, HPC, and distributed computing; and access relevant AI Tools faster and more easily with an expanded set of web-based selector options.
- Accelerate AI Workloads & Lower Compute Costs – Achieve performance improvements on new Intel CPUs and GPUs, including up to 14x with oneDNN on 5th Gen Intel® Xeon® Scalable processors1; 10x to 100x out-of-the-box acceleration of popular deep learning frameworks and libraries such as PyTorch* and TensorFlow*2; and faster gradient boosting inference across XGBoost, LightGBM, and CatBoost. Perform parallel computations at reduced cost with Intel® Extension for Scikit-learn* algorithms.
- Increase Innovation & Expand Deployment – Tune once and deploy universally with more efficient code offload using SYCL Graph, now available on multiple SYCL backends in the Intel oneAPI DPC++/C++ Compiler; ease CUDA-to-SYCL migration of more CUDA APIs in the Intel® DPC++ Compatibility Tool; and explore time savings in a CodePin Tech Preview (new SYCLomatic feature) to auto-capture test vectors and start validation immediately after migration. Codeplay adds new support and capabilities to its oneAPI plugins for NVIDIA and AMD GPUs.
The Nuts & Bolts
For those of you interested in diving into the component-level deets, here’s the collection.
Compilers
- Intel oneAPI DPC++/C++ Compiler is the first compiler to achieve SYCL 2020 conformance, giving developers confidence that their SYCL code is portable and reliably performs on the diversity of current and emergent GPUs. Enhanced SYCL Graph allows for seamless integration of multi-threaded work and thread-safe functions with applications and is now available on multiple SYCL backends, enabling tune-once-deploy-anywhere capability. Expanded conformance to OpenMP 5.0, 5.1, 5.2, and TR12 language standards enables increased performance.
- Intel® Fortran Compiler adds more Fortran 2023 language features including improved compatibility and interoperability between C and Fortran code, simplified trigonometric calculations, and predefined data types to improve code portability and ensure consistent behavior; makes OpenMP offload programming more productive; and increases compiler stability.
Performance Libraries
- Intel® oneAPI Math Kernel Library (oneMKL) introduces new optimizations and functionalities to reduce the data transfer between Intel GPUs and the host CPU, enables the ability to reproduce results of BLAS level 3 operations on Intel GPUs from run-to-run through CNR, and streamlines CUDA-to-SYCL porting via the addition of CUDA-equivalent functions.
- Intel® oneAPI Data Analytics Library (oneDAL) enables gradient boosting inference acceleration across XGBoost*, LightGBM*, and CatBoost* without sacrificing accuracy; improves clustering by adding spare K-Means support to automatically identify a subset of the features used in clustering observations.
- Intel® oneAPI Deep Neural Network Library (oneDNN) adds support for GPT-Q to improve LLM performance, fp8 data type in primitives and Graph API, fp16 and bf16 scale and shift arguments for layer normalization, and opt-in deterministic mode to guarantee results are bitwise identical between runs in a fixed environment.
- Intel® oneAPI DPC++ Library (oneDPL) adds a specialized sort algorithm to improve app performance on Intel GPUs, adds transform_if variant with mask input for stencil computation needs, and extends C++ STL style programming with histogram algorithms to accelerate AI and scientific computing.
- Intel® oneAPI Collective Communications Library (oneCCL) optimizes all key communication patterns to speed up message passing in a memory-efficient manner and improve inference performance.
- Intel® Integrated Performance Primitives expands features and support for quantum computing, cybersecurity, and data compression, including XMSS post-quantum hash-based cryptographic algorithm (tech preview), FIPS 140-3 compliance, and updated LZ4 lossless data compression algorithm for faster data transfer and reduced storage requirements in large data-intensive applications.
- Intel® MPI Library adds new features to improve application performance and programming productivity, including GPU RMA for more efficient access to remote memory and MPI 4.0 support for Persistent Collectives and Large Counts.
AI & ML Tools & Frameworks
- Intel® Distribution for Python* expands the ability to develop more future-proof code, including Data Parallel Control (dpctl) library’s 100% conformance to the Python Array API standard and support for NVIDIA devices; Data Parallel Extension for NumPy* enhancements for linear algebra, data manipulation, statistics, data types, plus extended support for keyword arguments; and Data Parallel Extension for Numba* improvements to kernel launch times.
- Intel Extension for Scikit-learn reduces the computational costs on GPUs by making computations only on changed dataset pieces with Incremental Covariance and performing parallel GPU computations using SPMD interfaces.
- Intel® Distribution of Modin* delivers significant enhancements in security and performance, including a robust security solution that ensures proactive identification and remediation of data asset vulnerabilities, and performance fixes to optimize asynchronous execution. (Note: in the 2024.2 release, developers will be able to access Modin through upstream channels.)
Analyzers & Debuggers
- Intel® VTune™ Profiler expands the ability to identify and understand the reasons of implicit USM data movements between Host and GPU causing performance inefficiencies in SYCL applications; adds support for .NET 8, Ubuntu* 23.10, and FreeBSD* 14.0.
- Intel® Distribution for GDB* rebases to GDB 14, staying current and aligned with the latest application debug enhancements; enables the ability to monitor and troubleshoot memory access issues in real time; and adds large General Purpose Register File debug mode support for more comprehensive debugging and optimization of GPU-accelerated applications.
Rendering & Ray Tracing
- Intel® Embree adds enhanced error reporting for SYCL platform and driver to smooth the transition of cross-architecture code; improves stability, security, and performance capabilities.
- Intel® Open Image Denoise fully supports multi-vendor denoising across all platforms: x86 and ARM CPUs (including ARM support on Windows*, Linux*, and macOS*) and Intel, NVIDIA, AMD, and Apple GPUs.
More Resources
- Intel Compiler First to Achieve SYCL 2020 Conformance
- A Dev's Take on the 2024.1 Release
- Download Codeplay oneAPI plugins: NVIDIA GPUs | AMD GPUs
Footnotes
1 Performance Index: 5th Gen Intel Xeon Scalable Processors
2 Software AI accelerators: AI performance boost for free
Gaudi and Xeon Advance Inference Performance for Generative AI
March 27, 2024 | Intel® Developer Cloud, MLCommons
Newest MLPerf results for Intel® Gaudi 2 accelerators and 5th Gen Intel® Xeon® processors demonstrate Intel is raising the bar for GenAI performance.
Today, MLCommons published results of the industry standard MLPerf v4.0 benchmark for inference, inclusive of Intel’s submissions for its Gaudi 2 accelerators and 5th Gen intel Xeon Scalable processors with Intel® AMX.
As the only benchmarked alternative to NVIDIA H100* for large language and multi-model models, Gaudi 2 offers compelling price/performance, important when gauging the total cost of ownership. On the CPU side, Intel remains the only server CPU vendor to submit MLPerf results (and Xeon is the host CPU for many accelerator submissions).
Get the details and results here.
Try them in the Intel® Developer Cloud
You can evaluate 5th Gen Xeon and Gaudi 2 in the Intel Developer Cloud, including running small- and large-scale training (LLM or generative AI) and inference production workloads at scale and managing AI compute resources. Explore the subscription options and sign up for an account here.
Intel Open Sources Continuous Profiler Solution, Automating Always-On CPU Performance Analysis
March 11, 2024 | Intel® Granulate™ Cloud Optimization Software
A continuous, autonomous way to find runtime efficiencies and simplify code optimization.
Today, Intel has released to open source the Continuous Profiler optimization agent, serving as another example of the company’s open ecosystem approach to catalyze innovation and boost productivity for developers.
As its name indicates, Continuous Profiler keeps perpetual oversight on CPU utilization, thereby offering developers, performance engineers, and DevOps an always-on and autonomous way to identify application and workload runtime inefficiencies.
How it works
It combines multiple sampling profilers into a single flame graph, which is a unified visualization of what the CPU is spending time on and, in particular, where high latency or errors are happening in the code.
Why you want it
Continuous Profiler comes with numerous unique features to help teams find and fix performance errors and smooth deployment, is compatible with Intel Granulate’s continuous optimization services, can be deployed cluster-wide in minutes, and supports a range of programming languages without requiring code changes.
Additionally, it’s SOC2-certified and held to Intel's high security standards, ensuring reliability and trust in its deployment, and is used by global companies including Snap Inc. (portfolio includes Snapchat and Bitmoji), ironSource (app business platform), and ShareChat (social networking platform).
Learn more
Intel® Software at KubeCon Europe 2024
February 29, 2024 | Intel® Software @ KubeCon Europe 2024
![]() Intel’s Enterprise Software Portfolio enables K8s scalability for enterprise applications
Intel’s Enterprise Software Portfolio enables K8s scalability for enterprise applications
Meet Intel enterprise software experts at KubeCon Europe 2024 (March 19-22) and discover how you can streamline and scale deployments, reduce Kubernetes costs, and achieve end-to-end security for data.
Plus, attend the session Above the Clouds with American Airlines to learn how one of the world’s top airlines achieved 23% cost reductions for their largest cloud-based workloads using Intel® Granulate™ software.
Why Intel Enterprise Software for K8s?
Because its Enterprise Software portfolio is purpose-built to accelerate cloud-native applications and solutions more efficiently, at scale, paving a faster way to AI. Meaning you can run production-level Kubernetes workloads the right way—easier to manage, secure, and efficiently scalable.
In a nutshell, you get:
- Optimized performance with reduced costs
- Better models with streamlined workflow
- Confidential computing that’s safe, secure, and compliant
Stop by Booth #J17 to have a conversation about the depth and breadth of Intel’s enterprise software solutions.
Explore Intel @ KubeCon EU 2024 →
More resources
Prediction Guard Offers Customers LLM Reliability and Security via Intel® Developer Cloud
February 22, 2024 | Intel® Developer Cloud
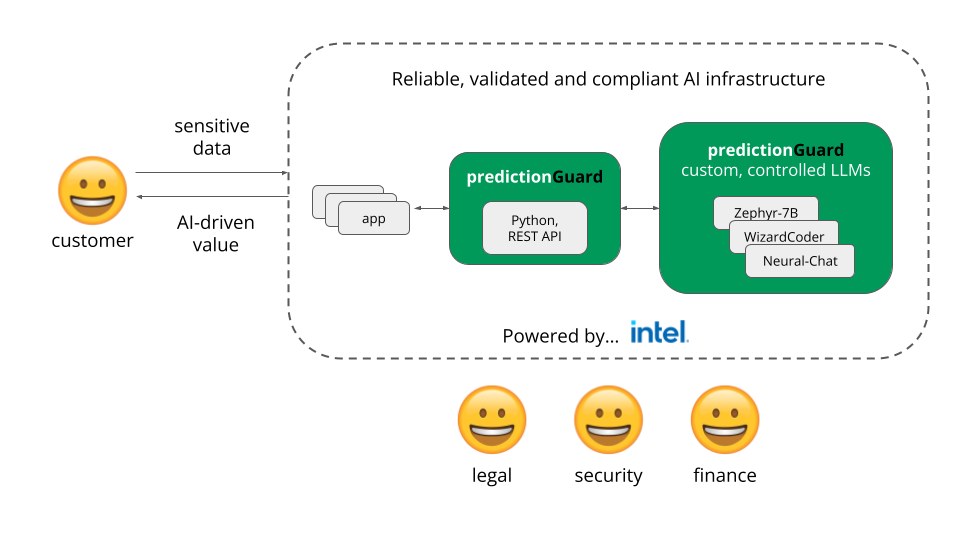 AI startup Prediction Guard is now hosting its LLM API in the secure, private environment of Intel Developer Cloud, taking advantage of Intel’s resilient computing resources to deliver peak performance and consistency in cloud operations for its customers’ GenAI applications.
AI startup Prediction Guard is now hosting its LLM API in the secure, private environment of Intel Developer Cloud, taking advantage of Intel’s resilient computing resources to deliver peak performance and consistency in cloud operations for its customers’ GenAI applications.
Prediction Guard’s AI platform enables enterprises to harness the full potential of large language models while mitigating security and trust issues such as hallucinations, harmful outputs, and prompt injections.
By moving to Intel Developer Cloud, the company can offer its customers significant and reliable computing power as well as the latest AI hardware acceleration, libraries, and frameworks: it’s currently leveraging Intel® Gaudi® 2 AI accelerators, the Intel/Hugging Face collaborative Optimum Habana library, and Intel extensions for PyTorch and Transformers.
“For certain models, following our move to Intel Gaudi 2, we have seen our costs decrease while throughput has increased by 2x.”
Learn more
Prediction Guard is part of the Intel® Liftoff for Startups, a free program for early-stage AI and machine learning startups that helps them innovate and scale across their entrepreneurial journey.
New Survey Unpacks the State of Cloud Optimization for 2024
February 20, 2024 | Intel® Granulate™ software
A newly released global survey conducted by the Intel® Granulate™ cloud-optimization team assessed key trends and strategies in cloud computing among DevOps, Data Engineering, and IT leaders at 413 organizations spanning multiple industries.
Among the findings, the #1 and #2 priorities for the majority of organizations (over 2/3) were cloud cost reduction and application performance improvement. And yet, 54% do not have a team dedicated to cloud-based workload optimization.
Get the report today to learn more trends, including:
- Cloud optimization priorities and objectives
- Assessment of current optimization efforts
- The most costly and difficult-to-optimize cloud-based workloads
- Optimization tools used in the tech stack
- Innovations for 2024
Download the report →
Request a demo →
American Airlines Achieves 23% Cost Reductions for Cloud Workloads using Intel® Granulate™
January 29, 2024 | Intel® Granulate™ Cloud Optimization Software
American Airlines (AA) partnered with Intel Granulate to optimize its most challenging workloads, which were stored in a Databricks data lake, and also mitigate the challenges of an untenable data-management price tag.
After deploying the Intel Granulate solution, which delivers autonomous and continuous optimization with no code changes or development efforts required, AA was able to free up engineering teams to process and analyze data at optimal pace and scale, run job clusters with 37% fewer resources, and reduce costs across all clusters by 23%.
Read the case study →
Request a demo →
Intel, the Intel logo, and Granulate are trademarks of Intel Corporation or its subsidiaries
Now Available: the First Open Source Release of Intel® SHMEM
January 10, 2024 | Intel® SHMEM [GitHub]
V1.0.0 of this open source library extends the OpenSHMEM programming model to support Intel® Data Center GPUs using the SYCL cross-platform C++ programming environment.
OpenSHMEM (SHared MEMory) is a parallel programming library interface standard that enables Single Program Multiple Data (SPMD) programming of distributed memory systems. This allows users to write a single program that executes many copies of the program across a supercomputer or cluster of computers.
Intel® SHMEM is a C++ library that enables applications to use OpenSHMEM communication APIs with device kernels implemented in SYCL. It implements a Partitioned Global Address Space (PGAS) programming model and includes a subset of host-initiated operations in the current OpenSHMEM standard and new device-initiated operations callable directly from GPU kernels.
Feature Highlights
- Supports the Intel® Data Center GPU Max Series
- Device and host API support for OpenSHMEM 1.5-compliant point-to-point RMA, Atomic Memory Operations, Signaling, Memory Ordering, and Synchronization Operations
- Device and host API support for OpenSHMEM collective operations
- Device API support for SYCL work-group and sub-group level extensions of Remote Memory Access, Signaling, Collective, Memory Ordering, and Synchronization Operations
- Support of C++ template function routines replacing the C11 Generic selection routines from the OpenSHMEM spec
- GPU RDMA support when configured with Sandia OpenSHMEM with suitable Libfabric providers for high-performance networking services
- Choice of device memory or USM for the SHMEM Symmetric Heap
Read the blog for all the details
(written by 3 Sr. Software Engineers @ Intel)
More resources
Updated: Codeplay oneAPI Plugins for NVIDIA GPUs
December 23, 2023
The recent release of 2024.0.1 Intel® Software Development Tools, comprised of oneAPI and AI tools, include noteworthy additions and improvements to Codeplay’s oneAPI plugins for NVIDIA GPUs.
The highlights:
- Bindless Images – a SYCL extension that represents a significant overhaul of the current SYCL 2020 images API.
- Users gain more flexibility over their memory and images.
- Enables hardware sampling and fetching capabilities for various image types like mipmaps and new ways to copy images like sub-region copies.
- Offers interoperability features with external graphics APIs like Vulkan and image-manipulation flexibility for integration with Blender.
- SYCL Support
- Non-uniform groups – allows developers to perform synchronization operations across some subset of the work items in a workgroup or subgroup.
- Peer-to-peer access – in a multi-GPU system, this may result in lower latency and/or better bandwidth in memory accesses across devices.
- Experimental version of SYCL-Graph – lets developers define ahead of time the operations they want to submit to the GPU, improving performance and saving time.
Additionally, the AMD plugin continues on the path of beta and toward production release in 2024.
Get the plugins
More resources
Intel’s Newest AI Acceleration CPUs + 2024.0 Software Development Tools = Innovation at Scale
December 14, 2023 | AI Everywhere keynote replay, Intel® Software Developer Tools 2024.0
Powering and optimizing AI workloads across data center, cloud, and edge.
Today marks the official launch of Intel’s latest AI acceleration platforms: 5th Gen Intel® Xeon® Scalable processors (codenamed Emerald Rapids) and Intel® Core™ Ultra processors (codenamed Meteor Lake). Announced by Pat Gelsinger at the “AI Everywhere” event this morning from Nasdaq in NYC, these systems provide developers and data scientists flexibility and choice for accelerating AI innovation at scale.
And the newly released Intel® Software Development Tools 2024.0 are ready to support applications and solutions targeting these platforms.
Here are some of the ways:
Targeting 5th Gen Intel® Xeon® Scalable processors
The 5th Gen is an evolution of the 4th Gen Intel Xeon platform and delivers impressive performance per watt plus outsized performance and TCO in AI, database, networking, and HPC.
Intel’s 2024.0 release of optimized tools, libraries, and AI frameworks powered by oneAPI give developers the keys to maximizing application performance by activating the advanced capabilities of Xeon—both 4th and 5th Gen, as well as Intel® Xeon® CPU Max Series:
- Intel® Advanced Matrix Extensions (Intel® AMX) built-in AI accelerator
- Intel® QuickAssist Technology (Intel® QAT) integrated workload accelerator
- Intel® Data Streaming Accelerator (Intel® DSA) for high-bandwidth, low-latency data movement
- Intel® In-Memory Analytics Accelerator (Intel® IAA) for very high throughput compression and decompression + primitive analytic functions
Software Tools for 4th & 5th Gen Intel Xeon & Max Series Processors
Targeting Intel Core Ultra processors
This combined CPU, GPU, and NPU (neural processing unit) platform is built on the new Intel 4 process and delivers an optimal balance of power efficiency and performance, immersive experiences, and dedicated AI acceleration for gaming, content creation, and productivity on the go.
Intel’s 2024.0 release helps ISVs, developers, and professional content creators optimize gaming, content creation, AI, and media applications by putting into action the new platform’s cutting-edge features, including:
- Intel® AVX-512
- Intel® AI Boost and inferencing acceleration
- AV1 encode/decode
- Ray-traced hardware acceleration
Software Tools for Intel Core Ultra Processor
Learn more
- Watch the keynote replay
- Read the press release
- Access a new quick start guide: Accelerate AI with Intel® AMX using PyTorch and TensorFlow optimizations, and OpenVINO™ toolkit

Now Available: 2024 Release of Intel Development Tools
November 20, 2023 | Intel® Software Development Tools
Expanding Multiarchitecture Performance, Porting & Productivity for AI & HPC
The 2024 Intel® Software Development Tools are available, bringing to developers even more multiarchitecture capabilities to accelerate and optimize AI, HPC, and rendering workloads across Intel CPUs, GPUs, and AI accelerators. Powered by oneAPI (now driven by the Unified Acceleration Foundation), the tools are based on open standards and broad coverage for C++, OpenMP, SYCL, Fortran, MPI and Python.
5 Key Benefits
(There are many, many more. See all the deets here. Read the blog here.)
- Future-Ready Programming – Accelerates performance on the latest Intel GPUs including added support for Python, Modin, XGBoost, and rendering; supports upcoming 5th Gen Intel® Xeon® Scalable and Intel® Core™ Ultra CPUs; and expands AI and HPC capabilities via broadened standards coverage across multiple tools.
- AI Acceleration – Speeds up AI and machine learning on Intel CPUs and GPUs with native support through Intel-optimized PyTorch and TensorFlow frameworks and improvements to data-parallel extensions in Python.
- Vector Math Optimizations – oneMKL integrates RNG offload on target devices for HPC simulations, statistical sampling, and more on x86 CPUs and Intel GPUs, and supports FP16 datatype on Intel GPUs.
- Expanded CUDA-to-SYCL Migration – Intel® DPC++ Compatibility Tool (based on open source SYCLomatic) adds CUDA library APIs and 20 popular applications in AI, deep learning, cryptography, scientific simulation, and imaging.
- Advanced Preview Features – These evaluation previews include C++ parallel STL for easy GPU offload, dynamic device selection to optimize compute node resource usage, SYCL graph for reduced GPU offload overhead thread composability to prevent thread oversubscription in OpenMP, and profile offloaded code to NPUs.
Discover the Power of Intel CPUs & GPUs + oneAPI
- The ATLAS Experiment achieves performance gains by implementing heterogeneous particle reconstruction on Intel GPUs optimized by Intel software tools, including benchmarking of SYCL and CUDA code on Intel and NVIDIA GPUs.
- STAC-A2 Benchmark implementation for oneAPI sets records on Intel GPUs versus NVIDIA.
- VMware and Intel deliver jointly validated AI stack to unlock private AI everywhere for model development and deployment.
Super News! HPCwire just announced its editors’ and readers choice awards for 2023—and Intel oneAPI software development tools and libraries landed the top readers’ choice for the best HPC Programming Tool or Technology. With developers and HPC experts driving new levels of HPC and AI innovation, this honor voted by them validates the importance of open, standards-based multiarchitecture programming. oneAPI has received either the editors’ or readers’ award each year since 2020. Thank you for this highly-esteemed accolade.
Accelerate & Scale AI Workloads in Intel® Developer Cloud
September 20, 2023 | Intel® Developer Cloud
Built for developers : access the latest Intel® CPUs, GPUs, and AI accelerators
As announced at Intel Innovation 2023, Intel® Developer Cloud is now publicly available. The platform offers developers, data scientists, researchers, and organizations a development environment with direct access to current and, in some cases, pre-release Intel hardware plus software services and tools, all in service to help them build, test, and optimize products and solutions for the newest tech features and bring them to market faster.
Both free and paid subscription tiers are available.
The current complement of hardware and software includes:
- Hardware
- 4th Gen Intel® Xeon® Scalable processors (single-node and multiarchitecture platforms and clusters)
- Intel® Xeon® CPU Max Series (for high bandwidth memory workloads)
- Intel® Data Center GPU Max Series (targeting the most demanding computing workloads)
- Habana® Gaudi®2 AI accelerator (for deep learning tasks)
- Software & Services
- Run small- and large-scale AI training, model optimization, and inference workloads such as Meta AI Llama 2, Databricks Dolly, and more
- Utilize small to large VMs, full systems, or clusters
- Access software tools including the Intel® oneAPI Base, HPC, and Rendering toolkits; Intel® Quantum SDK; AI tools and optimized frameworks such as Intel® OpenVINO™ toolkit, Intel-optimized TensorFlow and PyTorch, Intel® Neural Compressor, Intel® Distribution for Python, and several more
And more will be added all the time.
Intel, the Intel logo and Gaudi are trademarks of Intel Corporation or its subsidiaries.
Intel Innovation 2023 At a Glance
September 20, 2023 | Intel® Innovation
Intel’s premier 2-day developer event was attended by nearly 2,000 attendees who participated in a wealth of sessions—keynotes from CEO Pat Gelsinger, other Intel leaders, and industry luminaries; hands-on labs; tech-insights panels; training sessions; and more—focused on the latest breakthroughs in AI spanning hardware, software, services, and advanced technologies.
There were many highlights and announcements. Here are 6 of them:
- Welcome to the “Siliconomy”. Pat introduced the term in his opening—a new era of global expansion where computing is foundational to a bigger opportunity and better future for every person on the planet—and its role in a world where AI is delivering a generational shift in computing. Read his Siliconomy editorial [PDF]
- Intel® Developer Cloud general availability. Developers can accelerate and scale AI in this free and paid development environment with access to the latest Intel hardware and software to build, test, optimize, and deploy AI and HPC applications and workloads. Includes a depth and breadth of hardware and software tools & services such as 4th Gen Intel® Xeon® Scalable & Max Series processors, Intel® Data Center GPU Max Series processors, Habana® Gaudi®2 AI accelerators, oneAPI tools and Intel-optimized AI tools and frameworks, and SaaS options such as Hugging Face BLOOM, Meta AI Llama 2, Databricks Dolly, and many more. Explore Intel Developer Cloud.
- Intel joins the Unified Acceleration (UXL) Foundation. An evolution of the oneAPI open programming model, the Linux Foundation formed the UXL Foundation to establish cross-industry collaboration on an open-standard accelerator programming model that simplifies development of cross-platform applications. Read the blogs from Sanjiv Shah (GM Developer Software @ Intel) and Rod Burns (VP Ecosystem @ Codeplay)
- Intel® Certified Developer – MLOps Professional. This new certification program, taught by MLOps experts, uses self-paced modules, hands-on labs, and practicums to teach you how to incorporate compute awareness into the AI solution design process, maximizing performance across the AI pipeline. Explore the program.
- Intel® Trust Authority. This suite of trust and security services provides customers with assurance that their apps and data are protected on the platform of their choice, including multiple cloud, edge, and on-premises environments. Explore Intel Trust Authority | Start a 30-day free trial.
- New Enterprise Software & Services portfolio. The new collection is designed to solve some of the biggest enterprise challenges by delivering a scalable, sustainable tech stack with built-in, silicon-based security. Includes products that simplify security [Intel Trust Authority], deliver enterprise AI with more ROI [Intel Developer Cloud + Cnvrg.io], and improve application performance with real-time autonomous workload optimization [Intel® Granulate].

More to explore:
Intel, the Intel logo and Gaudi are trademarks of Intel Corporation or its subsidiaries.
Unified Acceleration Foundation Forms to Drive Open, Accelerated Compute & Cross-Platform Performance
September 19, 2023 | Unified Acceleration Foundation
Today, the Linux Foundation announced the formation of the Unified Acceleration (UXL) Foundation, a cross-industry group committed to delivering an open-standard, accelerator programming model that simplifies development of performant, cross-platform applications.
An evolution of the oneAPI initiative, the UXL Foundation marks the next critical step in driving innovation and implementing the oneAPI specification across the industry. It includes a distinguished list of participating organizations and partners, including Arm, Fujitsu, Google Cloud, Imagination Technologies, Intel and Qualcomm Technologies, Inc., and Samsung. These industry leaders have come together to promote open source collaboration and development of a cross-architecture, unified programming model.
“The Unified Acceleration Foundation exemplifies the power of collaboration and the open-source approach. By uniting leading technology companies and fostering an ecosystem of cross-platform development, we will unlock new possibilities in performance and productivity for data-centric solutions.”
More resources
- Our kid’s graduating from college!, Sanjiv Shah, GM of Developer Software Engineering, Intel
- Announcing the Unified Acceleration (UXL) Foundation, Rod Burns, VP Ecosystem @ Codeplay Software
Pre-set AI Tool Bundles Deliver Enhanced Productivity
August 21, 2023 | AI Tools Selector (beta)
Choose the tools you need with new, flexible AI tool installation service
Intel's AI Tools Selector (beta) is now available, delivering streamlined package installation of popular deep learning frameworks, tools, and libraries. Install them individually or in pre-set bundles for data analytics, classic machine learning, deep learning, and inference optimization.
The tools:
- Deep learning frameworks:
- Intel® Extension for TensorFlow
- Intel® Extension for PyTorch
- Tools & libraries:
- Intel® Optimization for XGBoost
- Intel® Optimization for Scikit-learn
- Intel® Distribution of Modin
- Intel® Neural Compressor
- SDKs & Command-line Interfaces (CLIs):
- cnvrg.io SDK v2 in Python
All are available via conda, pip, or Docker package managers.
Bookmark the AI Tools Selector (beta) →
Speed Up AI & Gain Productivity with Advances in Intel AI Tools
August 11, 2023 | Intel® AI Analytics Toolkit, oneDAL, oneDNN, oneCCL
Calling all AI practitioners, performance engineers, and framework builders ...
Speed up deep learning and machine learning on Intel® CPUs and GPUs with the just-released 2023.2 Intel® AI Analytics Toolkit and updated oneAPI libraries.
The latest advances in these tools help improve performance, enhance productivity, and increase cross-platform code portability for end-to-end data science and analytics pipelines.
The Highlights
Improved Performance
- Faster deep learning with PyTorch 2.0 compatibility and experimental support for Intel® Arc™ A-Series Graphics cards with Intel® Extension for PyTorch. If TF is more your jam, Intel® Extension for TensorFlow makes it easier to take full advantage of new CPU optimizations to streamline execution, memory allocation, and task scheduling.
- Faster, classic machine learning with Intel® Extension for Scikit-learn, now featuring CPU optimizations for extremely random trees and Intel® oneAPI Data Analytics Library (oneDAL) distributed algorithms. For GPUs, the Intel® Optimization for XGBoost now supports Intel® Data Center GPU Max Series.
- Accelerated data preprocessing with pandas 2.0 support in Intel® Distribution for Modin, which combines faster memory-efficient operations with the scaling benefits of parallel and distributed computing.
Enhanced Productivity
- New model compression automation in Intel® Neural Compressor delivers streamlined quantization, easier accuracy debugging, validation for popular new LLMs, and better framework compatibility with PyTorch, TensorFlow, and ONNX-Runtime.
- Improved prediction accuracy for training & inference with new missing values support when using daal4py Model Builders to convert gradient boosting models to use optimized algorithmic building blocks found in oneDAL.
Increased Portability
- Expanded hardware choice including support for ARM, NVIDIA, and AMD platforms as well as new performance optimizations in Intel CPUs and GPUs such as simpler debug and diagnostics and an experimental Graph compiler backend. All available using Intel® oneAPI Deep Neural Network Library (oneDNN).
- Enhanced scaling efficiency in the cross-platform Intel® oneAPI Collective Communication Library (oneCCL) features new support for Intel® Data Streaming Accelerator, found in 4th Gen Intel® Xeon® Scalable processors.
Learn More
Download the Intel AI Analytics Toolkit →
Explore the release notes for more details
Advancing AI Everywhere: Intel Joins the PyTorch Foundation
August 10, 2023 | PyTorch Optimizations from Intel
Intel has just joined the PyTorch Foundation as a Premier member and will take a seat on its Governing Board to help accelerate the development and democratization of PyTorch.
According to its website, the Foundation “is a neutral home for the deep learning community to collaborate on the open source PyTorch framework and ecosystem.” Its mission is “to drive adoption of AI and deep learning tooling by fostering and sustaining an ecosystem of open source, vendor-neutral projects with PyTorch.”
It’s a good fit. Intel has been contributing to the framework since 2018, an effort precipitated by the vision of democratizing access to AI through ubiquitous hardware and open software. As an example, the newest Intel PT optimizations and features are regularly released in the Intel® Extension for PyTorch before they’re upstreamed into stock PyTorch. This advanced access to pre-stock-version enhancements helps data scientists and software engineers maintain a competitive edge, developing AI applications that take advantage of the latest hardware technologies.
Download the Intel® Extension for PyTorch
Proven Performance Improvements with Intel/Accenture AI Reference Kits
July 24, 2023 | AI Reference Kits
These Pre-Configured Kits Simplify AI Development
Likely you’ve seen mention of them here—a total of 34 free, drop-in solutions for AI workloads spanning consumer products, energy and utilities, financial services, health and life sciences, manufacturing, retail, and telecommunications.
The new news is that multiple industries are seeing measurable benefits from leveraging the code and capabilities inherent in them.
Here’s a sampling:
- Using the AI reference kit designed to set up interactions with an enterprise conversational AI chatbot was found to inference in batch mode up to 45% faster with oneAPI optimizations.1
- The AI reference kit designed to automate visual quality control inspections for Life Sciences demonstrated training up to 20% faster and inferencing 55% faster for visual defect detection with oneAPI optimizations.2
To predict utility-asset health and deliver higher service reliability, there is an AI reference kit that provides up to a 25% increase in prediction accuracy.3
Now Available: 2023.2 Release of Intel® oneAPI Tools
July 20, 2023 | Intel® oneAPI Tools
Extending & strengthening software development for open, multiarchitecture computing.
The just-released 2023.2 Intel® oneAPI tools bring the freedom of multiarchitecture software development to Python, simplify migration from CUDA to open SYCL, and ramp performance on the latest GPU and CPU hardware.
Benefits of the 2023.2 Release
If you haven’t updated your tools to the oneAPI multiarchitecture versions—or if you haven’t tried them at all—here are 5 benefits of doing so with this release:
- Simplified Migration from CUDA to Performant SYCL – Developers now can experience streamlined CUDA-to-SYCL migration for popular applications such as AI, deep learning, cryptography, scientific simulation, and imaging; plus, the new release supports additional CUDA APIs, the latest version of CUDA, and FP64 for broader migration coverage.
- Faster & More Accurate AI Inferencing – The addition of NaN (Not a Number) values support during inference streamlines pre-processing and boosts prediction accuracy for models trained on incomplete data.
- Accelerated AI-based Image Enhancement on GPUs – Intel® Open Image Denoise ray-tracing library now supports GPUs from Intel and other vendors, providing hardware choice for fast, high-fidelity, AI-based image enhancements.
- Faster Python for AI & HPC – This release introduces the beta version Data Parallel Extensions for Python, extending numerical Python capabilities to GPUs for NumPy and cuPy functions, including Numba compiler support.
- Streamlined Method to Write Efficient Parallel Code – Intel® Fortran Compiler extends support for DO CONCURRENT Reductions, a powerful feature that allows the compiler to execute loops in parallel and significantly improve code performance while making it easier to write efficient and correct parallel code.
2023.2 Highlights at the Tool Level
Compilers & SYCL Support
- Intel® oneAPI DPC++/C++ Compiler sets the immediate command lists feature as its default, benefitting developers looking to offload computation to Intel® Data Center GPU Max Series.
- Intel® oneAPI DPC++ Library (oneDPL) improves performance of the C++ STD Library sort and scan algorithms when running on Intel® GPUs; this speeds up these commonly used algorithms in C++ applications.
- Intel® DPC++ Compatibility Tool (based on the open source SYCLomatic project) adds support for CUDA 12.1 and more function calls, streamlines migration of CUDA to SYCL across numerous domains (AI, cryptography, scientific simulation, imaging, and more), and adds FP64 awareness to migrated code to ensure portability across Intel GPUs with and without FP64 hardware support.
- Intel® Fortran Compiler adds support for DO CONCURRENT Reduction, a powerful feature that can significantly improve the performance of code that performs reductions while making it easier to write efficient parallel code.
AI Frameworks & Libraries
- Intel® Distribution of Python introduces Parallel Extensions for Python (beta) which extends the CPU programming model to GPU and increases performance by enabling CPU and GPU for NumPy and CuPy.
- Intel® oneAPI Deep Neural Network Library (oneDNN) enables faster training & inference for AI workloads; simpler debug & diagnostics; support for graph neural network (GNN) processing; and improved performance on a multitude of processors such as 4th Gen Intel® Xeon® Scalable processors and GPUs from Intel and other vendors.
- Intel® oneAPI Data Analytics Library (oneDAL) Model Builder feature adds missing values for NaN support during inference, streamlining pre-processing and boosting prediction accuracy for models trained on incomplete data.
Performance Libraries
- Intel® oneAPI Math Kernel Library (oneMKL) drastically reduces kernel launch time on Intel Data Center GPU Max and Flex Series processors; introduces LINPACK benchmark for GPU.
- Intel® MPI Library boosts message-passing performance for 4th Gen Intel Xeon Scalable and Max CPUs, and adds important optimizations for Intel GPUs.
- Intel® oneAPI Threading Building Blocks (oneTBB) algorithms and Flow Graph nodes now can accept new types of user-provided callables, resulting in a more powerful and flexible programming environment.
- Intel® Cryptography Primitives Library multi-buffer library now supports XTS mode of the SM4 algorithm, benefitting developers by providing efficient and secure ways of encrypting data stored in sectors, such as storage devices.
Analysis & Debug
- Intel® VTune™ Profiler delivers insights into GPU-offload tasks and execution, improves application profiling support for BLAS level-3 routines on Intel GPUs, and identifies Intel Data Center GPU Max Series devices in the platform diagram.
- Intel® Distribution for GDB rebases to GDB 13, staying current and aligned with the latest enhancements supporting effective application debug and debug for Shared Local Memory (SLM).
Learn More
- Explore Intel oneAPI & AI tools →
- New to SYCL? Get started here →
- Bookmark the oneAPI Training Portal – Learn the way you want to with learning paths, tools, on-demand training, and opportunities to share and showcase your work.
Notices and Disclaimers
Codeplay is an Intel company.
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Results may vary.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates.
No product or component can be absolutely secure. Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy
Blender 3.6 LTS Includes Hardware-Accelerated Ray Tracing through Intel® Embree on Intel® GPUs
June 29, 2023 | Intel® Embree, Blender 3.6 LTS
Award-winning Intel® Embree is now part of the Blender 3.6 LTS release. With this addition of Intel’s high-performance ray tracing library, content creators can now take advantage of hardware-accelerated rendering for Cycles on Intel® Arc™ GPUs and Intel® Data Center Flex and Max Series GPUs while significantly decreasing rendering times with no loss in fidelity.
The 3.6 release also includes premier AI-based denoising through Intel® Open Image Denoise. Both tools are part of the Intel® oneAPI Rendering Toolkit (Render Kit), a set of open source rendering and ray tracing libraries for creating high-performance, high-fidelity visual experiences.
- Read the blog (includes benchmarks)
- Watch the demo [6:20]
- Download Blender 3.6 LTS
- Download the Render Kit
UKAEA Makes Fusion a Reality using Intel® Hardware and oneAPI Software Tools
June 29, 2023 | Intel® oneAPI Tools
Using Intel® hardware, oneAPI tools, and distributed asynchronous object storage (DAOS), the UK Atomic Energy Authority and the Cambridge Open Zettascale Lab are developing the next-generation engineering tools and processes necessary to design, certify, construct, and regulate the world’s first fusion powerplants in the United Kingdom. This aligns with the U.K.’s goals to accelerate the roadmap to commercial fusion power by the early 2040s.
The UKAEA team used supercomputing and AI to design the fusion power plant virtually. It will subsequently run a number of HPC workloads on a variety of architectures, including 4th Gen Intel® Xeon® processors as well as multi-vendor GPUs and FPGAs.
Why This Matters
Being able to program once for multiple hardware is key. By using oneAPI open, standards-based, multiarchitecture programming, the UKAEA team can overcome barriers of code portability and deliver performance and development productivity without vendor lock-in.
Learn more:
Resources:
Introducing the oneAPI Construction Kit
June 5, 2023
Codeplay brings open, standards-based SYCL programming to new, custom, and specialist hardware
Today Codeplay announced the latest extension of the oneAPI ecosystem with an open source project that allows code written in SYCL to run on custom architectures for HPC and AI.
The oneAPI Construction Kit includes a reference implementation for RISC-V vector processors but can be adapted for a range of processors, making it easy to access a wealth of supported SYCL libraries.
A benefit for users of custom architectures, rather than having to learn a new custom language, they can instead use SYCL to write high-performance applications efficiently – using a single codebase that works across multiple architectures. This means less time spent on porting efforts and maintaining separate codebases for different architectures, and more time for innovation.
What’s Inside the New Kit:
- A framework for bringing oneAPI support to new and innovative hardware – such as specialized AI accelerators
- Support for x86, ARM, and RISC-V targets
- Documentation
- Reference Design
- Tutorials
- Modular Software Components
Learn More & Get It
- Get it free at developer.codeplay.com
- Watch the demo [2:32]
- Read the blog from Codeplay Principal SW Engineer, Colin Davidson
- Get the documentation
Intel Delivers AI-Accelerated HPC Performance, Uplifted by oneAPI
May 22, 2023 | Intel® oneAPI Tools
ISC’23 takeaway: Broadest, most open HPC+AI portfolio powers performance, generative AI for science
Intel’s keynote at International Super Computing 2023 underscored how the company is making multiarchitecture programming easier for an open ecosystem, as well as driving competitive performance for diverse HPC and AI workloads based on a broad product portfolio of CPUs, GPUs, AI accelerators, and oneAPI software.
Here are the highlights.
Hardware:
- Independent software vendor Ansys showed the Intel® Data Center GPU Max Series outperforms NVIDIA H100 by 50% on AI-accelerated HPC applications, in addition to an average improvement of 30% over H100 on diverse workloads.*
- The Habana Gaudi 2 deep learning accelerator delivers up to 2x faster AI performance over NVIDIA A100 for DL training and inference.*
- Intel® Xeon CPUs (including the Max Series and 4th Gen) deliver, respectively, 65% speedup over AMD Genoa for bandwidth-limited problems and 50% average speed-up over AMD Milan.*
Software:
- Worldwide, about 90% of all developers benefit from or use software developed for or optimized by Intel.*
- oneAPI has been demonstrated on diverse CPU, GPU, FPGA and AI silicon from multiple hardware providers, addressing the challenges of single-vendor accelerated programming models.
- New features in the latest oneAPI tools—such as OpenMP GPU offload, extended support for OpenMP and Fortran, and optimized TensorFlow and PyTorch frameworks and AI tools—unleash the capabilities of Intel’s most advanced HPC and AI CPUs and GPUs.
- Real-time, ray-traced scientific visualization with hardware acceleration is now available on Intel GPUs, and AI-based denoising completes in milliseconds.
The oneAPI SYCL standard implementation has been shown to outperform NVIDIA native system languages; case in point: DPEcho SYCL code run on Max Series GPU outperformed by 48% the same CUDA code run on NVIDIA H100.
Intel is committed to serving the HPC and AI community with products that help customers and end-users make breakthrough discoveries faster. Our product portfolio spanning Xeon Max Series CPUs, Max Series GPUs, 4th Gen Xeon and Gaudi 2 are outperforming the competition on a variety of workloads, offering energy and total cost of ownership advantages, democratizing AI and providing choice, openness and flexibility.
Intel Flex Series GPUs Expanded with Open Software Stack
May 18, 2023 | Software for Intel® Data Center GPU Flex Series
New software updates optimize workloads for cloud gaming, AI inference, media acceleration & digital content creation
Introduced as a flexible, general-purpose GPU for the data center and the intelligent visual cloud, the Intel® Data Center GPU Flex Series was expanded with new production-level software to optimize workloads for cloud gaming, AI inference, media acceleration, digital content creation, and more. This GPU platform has an open and full software stack, no licensing fees, and a unified programming model for CPUs and GPUs for performance and productivity via oneAPI.
New Software Capability Highlights:
- Windows Cloud Gaming – Tap into the GPU’s power for remote gaming with a new reference stack.
- AI Inference – Boost deep learning and visual inference in applications used for smart city, library indexing and compliance, AI-guided video enhancement, intelligent traffic management, smart buildings and factories, and retail.
- Digital Content Creation – Deliver real-time rendering tapping into dedicated hardware acceleration, complete AI-based denoising in milliseconds.
- Autonomous Driving – Utilize Unreal Engine 4 to advance training and validation of AD systems.
Learn what comprises the open software stack, available tools, and how to get started with pre-configured containers.
2023.1.1 Release of Intel AI Analytics Toolkit Includes New Features & Fixes
May 3, 2023 | Intel® AI Analytics Toolkit
The latest release of the AI Kit continues to help AI developers, data scientists, and researchers accelerate end-to-end data science and analytics pipelines on Intel® architecture.
Highlights
- Intel® Neural Compressor optimizes auto- and multi-node tuning strategy and large language model (LLM) memory.
- Intel® Distribution of Modin introduces a new, experimental NumPy API that provides basic support for distributed numerical calculations.
- Model Zoo for Intel® Architecture now supports Intel® Data Center GPU Max Series and extends support for dataset downloader and data connectors.
- Intel® Extension for TensorFlow now supports TensorFlow 2.12 and adds Ubuntu 22.04 and Red Hat Enterprise Linux 8.6 to the list of supported platforms.
- Intel® Extension for PyTorch is now compatible with Intel® oneAPI Deep Neural Network Library (oneDNN) 3.1, which improves on PyTorch 1.13 operator coverage.
See the AI KIt release notes for full details.
More References
Explore Ready-to-Use Code Samples for CPUs, GPUs, and FPGAs
April 20, 2023 | oneAPI & AI Code Samples
Intel’s newly launched Code Samples portal provides direct access to a sizable (and always growing) collection of open source, high-quality, ready-to-use code that can be used to develop, offload, and optimize multiarchitecture applications.
Each sample is purpose-built to help any developer at any level understand concepts and techniques for adapting parallel programming methods to heterogeneous compute; they span high-performance computing, code and performance optimization, AI and machine learning, and scientific or general graphics rendering.
No matter their experience level, developers can find a variety of useful samples—all resident in the GitHub repository—with helpful instructions and commented code.
VMWare-Intel Collaboration Delivers Video and Graphics Acceleration via AV1 Encode/Decode on Intel® GPUs
April 11, 2023 | Intel® Arc™ Graphics, Intel® Data Center GPU Flex Series
Next-gen, multimedia codec offers more compression efficiency and performance
The latest release of VMware Horizon supports Intel® GPUs and provides media acceleration enabled by Intel® oneAPI Video Library (oneVPL). With Intel GPU support, VMware customers have greater choice, flexibility, and cost options on a wider range of hardware systems for deployment without being locked to a single GPU vendor. Running VMware Horizon on systems with Intel GPUs does not require license server setup, licensing costs, or ongoing support costs.
This Horizon release for desktops and servers utilizes AV1 encoding, optimized by oneVPL, on both Intel® Arc™ graphics and Intel® Data Center GPU Flex Series. The solution also delivers fast hardware encoding on supported Intel® Xe architecture-based and newer GPUs (integrated and discrete). With a GPU-backed virtual machine (VM), users can have a better media experience with improved performance, reduced latency, more consistent frames per second, and lower CPU utilization.
Now Available: Intel® oneAPI 2023.1 Tools
April 4, 2023 | Intel® oneAPI and AI Tools
Delivering new performance and code-migration capabilities
The just-released Intel® oneAPI 2023.1 tools augment the latest Intel® architecture features with high-bandwidth memory analysis, photorealistic ray tracing and path guiding, and extended CUDA-to-SYCL code migration support. Additionally, they continue to support the latest update of Codeplay’s oneAPI plugins for NVIDIA and AMD that make it easier to write multiarchitecture SYCL code. (These free-to-download plugins deliver quality improvements, support Joint_matrix extension and CUDA 11.8/testing 12, and enable gfx1032 for AMD. The AMD plugin backend now works with ROCm 5.x driver.)
2023.1 Highlights:
Compilers & SYCL Support
- Intel® oneAPI DPC++/C++ Compiler delivers AI acceleration with BF16 full support, auto-CPU dispatch, and SYCL kernel properties, and adds more SYCL 2020 and OpenMP 5.0 and 5.1 features to improve productivity and boost CPU and GPU performance.
- Intel® oneAPI DPC++ Library (oneDPL) improves performance of the sort, scan, and reduce algorithms.
- Intel® DPC++ Compatibility Tool (based on the open source SYCLomatic project) delivers easier CUDA-to-SYCL code migration with support for the latest release of CUDA’s headers, and adds more equivalent SYCL language and oneAPI library mapping functions such as runtime, math, and neural network domains.
Performance Libraries
- Intel® oneAPI Math Kernel Library (oneMKL) improves data center GPU performance via new real FFTs, plus 1D and 2D optimizations, random number generators, and Sparse BLAS and LAPACK inverse optimizations.
- Intel® MPI Library enhances performance for collectives using GPU buffers and default process pinning on CPUs with E-cores and P-cores.
- Intel® oneAPI Threading Building Blocks (oneTBB) improves robustness of thread-creation algorithms on Linux and provides full support of Thread Sanitizer on macOS and full-hybrid Intel® CPU support.
- Intel® oneAPI Data Analytics Library (oneDAL) is reduced in size by 30%.
- Intel® oneAPI Collective Communications Library (oneCCL) improves scaling efficiency of the Scaleup algorithms for Alltoall and Allgather and adds collective selection for scaleout algorithm for device (GPU) buffers.
- Intel® Integrated Performance Primitives (Intel® IPP) expands cryptography offerings with CCM/GCM modes, which enables Crypto Multi-Buffer for greater performance compared to scalar implementations, and adds support for asymmetric cryptographic algorithm SM2 for key exchange protocol and encryption/decryption APIs.
Analysis & Debug
- Intel® VTune™ Profiler identifies the best profile to gain performance utilizing high-bandwidth memory (HBM) on Intel® Xeon® Processor Max Series. It displays Xe Link cross-card traffic issues such as CPU/GPU imbalances, stack-to-stack traffic, and throughput and bandwidth bottlenecks on Intel® Data Center GPU Max Series.
- Intel® Distribution for GDB adds debug support for Intel® Arc™ GPUs on Windows and improves the debug performance on Linux for Intel discrete GPUs.
Rendering & Visual Computing
- Intel® Open Path Guiding Library (Intel® Open PGL) is integrated in Blender and Chaos V-Ray and provides state-of-the-art path-guiding methods for rendering.
- Intel® Embree supports Intel Arc GPUs and Intel® Data Center GPU Flex Series, and delivers performance increases on 4th Gen Intel® Xeon® processors per Phoronix benchmarks.
- Intel® OSPRay Studio add functionality from open Tiny EXR, Tiny DNG (for .tiff files), and Open Image IO.
oneAPI tools drive ecosystem innovation
oneAPI tools adoption is ramping multiarchitecture programming on new accelerators, and the ecosystem is rapidly pioneering unique solutions using the open, standards-based, unified programming model. Here are the most recent:
- Cross-platform: Purdue University launched a oneAPI Center of Excellence to advance AI and HPC teaching in the United States.
- Cloud: University of Tennessee launched oneAPI Center-of-Excellence Research which enabled a cloud-based Rendering as a Service (RaaS) learning environment for students.
- AI: Hugging Face accelerated PyTorch Transformers on 4th Gen Intel Xeon processors (explore part 1 and part 2), and HippoScreen increased AI performance by 2.4x to improve efficiency and build deep learning models.
- Graphics & Ray Tracing: Thousands of artists, content creators, and 3D experts can easily access advanced ray tracing, denoising, and path guiding capabilities through Intel rendering libraries integrated in popular renderers including Blender, Chaos V-Ray, and DreamWorks open source MoonRay.
Learn More
- Explore Intel oneAPI & AI tools >
- New to SYCL? Get started here >
- Bookmark the oneAPI Training Portal – Learn the way you want to with learning paths, tools, on-demand training, and opportunities to share and showcase your work.
Notices and Disclaimers
Codeplay is an Intel company.
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Results may vary.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates.
No product or component can be absolutely secure. Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy
Purdue Launches oneAPI Center of Excellence to Advance AI & HPC Teaching in the U.S.
March 27, 2023 | oneAPI, Intel® oneAPI Toolkits
Building oneAPI multiarchitecture programming concepts into the ECE curriculum
Purdue University will establish a oneAPI Center of Excellence on its West Lafayette campus. Facilitated through Purdue University’s Elmore Family School of Electrical and Computer Engineering (ECE), the center will take students’ original AI and HPC research projects to the next level through teaching oneAPI in the classroom.
The facility will use curated content from Intel including teaching kits and certified instructor courses, and students will have access to the latest Intel® hardware and software via the Intel® Developer Cloud.
“Purdue’s track record as one of the most innovative universities in America with its world-changing research, programs and culture of inclusion is a perfect fit for the oneAPI Center of Excellence. By giving Purdue students access to the latest AI software and hardware, we’ll see the next generation of developers, scientists and engineers delivering innovations that will change the world. We’re excited to assist Purdue in embracing the next giant leap in accelerated computing.”
Just Released the 6 Final AI Reference Kits
March 24, 2023 | AI Reference Kits
A Total of 34 Kits to Streamline AI Solutions
The final six AI reference kits, powered by oneAPI, are now available to help data scientists and developers more easily and quickly develop and deploy innovative business solutions with maximum performance on Intel® hardware:
- Visual Process Discovery for detecting UI elements in real time from inputted website screenshots (e.g., buttons, links, texts, images, headings, fields, labels, iframes) that users interacted with.
- Text Data Generation for generating synthetic text, such as the provided source dataset, using a large language model (LLM).
- Image Data Generation for generating synthetic images using generative adversarial networks (GANs).
- Voice Data Generation for translating input text data to generate speech using transfer learning with VOCODER models.
- AI Data Protection for minimizing challenges with PII (personally identifiable information) in the design and development stages such as data masking, data de-identification, and anonymization.
- Engineering Design Optimization for helping manufacturing engineers generate realistic designs whilst reducing manufacturing costs and accelerating product development processes.
Learn more about the AI ref kits
DreamWorks Animation’s Open Source MoonRay Software Optimized via Intel® Embree
March 15, 2023 | Intel® oneAPI Rendering Toolkit
Advancing Open Rendering Innovation
DreamWorks Animation’s production renderer is now open source, with photo-realistic ray-tracing acceleration provided by Intel® Embree, a high-performance ray-tracing library that’s part of the oneAPI Rendering Toolkit.
Formerly an in-house Monte Carlo ray tracer, Dreamworks’ MoonRay team worked with beta testers to adapt the code base—including enhancements and features—so it could be built and run outside of the company’s pipeline environment.
“As part of this release and in collaboration with DreamWorks, MoonRay users have access to Intel® technologies, Intel Embree, and oneAPI tools, as building blocks for an open and performant rendering ecosystem.”
2023.1 Release of Intel® AI Analytics Toolkit Supports Newest Intel® GPUs & CPUs
February 10, 20232 | Intel® AI Analytics Toolkit (AI Kit), AI Reference Kits
Powered by oneAPI to Maximize Multiarchitecture Performance
Today Intel launched the newest release of its AI Kit, with tools optimized to set free the full power of the latest GPUs (Intel® Data Center GPU Max Series and Intel® Data Center GPU Flex Series) and CPUs (4th Gen Intel® Xeon® Scalable and Intel® Xeon® Max Series processors).
Using the latest Toolkit, developers and data scientists can more effectively and efficiently accelerate end-to-end training and inference of their AI workloads, particularly on the new hardware.
Download the 2023.1 Intel AI Analytics Toolkit
New Software Features and Hardware Support
Here are some of the highlights. Get the full details in the release notes.
- Build DL models optimized for improved inference and performance with quantization and distillation; includes support for Intel® Extension for TensorFlow v1.1.0, Intel® Extension for PyTorch v1.13.0, PyTorch 1.13, and TensorFlow 2.10.
- Enable tuning strategy refinement, training for sparsity (block wise) enhancements, and Neural Coder integration.
- In Intel Xeon processors, deliver superior DL performance by enabling advanced capabilities (including Intel® AMX, Intel® AVX-512, VNNI, and bfloat16).
- In Data Center GPUs, deliver the same with Intel® XMX.
Model Zoo for Intel® Architecture [github]
- New precisions—BF32 and FP16 for PyTorch BERT Large + Intel Neural Compressor INT8 quantized models—support TensorFlow image-recognition topologies ResNet50, ResNet101, MobileNetv1, and Inception v3).
- Supports Intel® Data Center Flex Series for Intel Optimization for PyTorch and Intel Extension for TensorFlow.
Intel® Extension for TensorFlow [github]
- Supports Intel Data Center GPUs and includes Intel® Optimization for Horovod v0.4 to support distributed training on the new GPU Max Series.
- Co-works with stock TensorFlow 2.11 and 2.10.
Intel® Optimization for PyTorch
- Improve training and inference with native Windows support for ease-of-use/integration and BF16 and INT8 operator optimizations with oneDNN quantization backend.
- Improve performance on the new Intel CPUs and GPUs when used with Intel’s PyTorch extension.
- oneDNN and optimized deep learning frameworks, including TensorFlow and PyTorch, enable Intel® Xe Matrix Extensions (Intel® XMX) on the data center GPUs delivering increased, competitive performance across a wide range of market segments.
- Additional performance gains are provided by Intel’s extensions for TensorFlow and PyTorch, both of which have native GPU support.
Learn More
- Build, Deploy & Scale AI Solutions across the Enterprise
- Intel® AI & Machine Learning Tools
- Explore workload types, oneAPI tools, and other resources for the new GPUs and CPUs
- AI Analytics Code Samples [github]
- Intel Extension for PyTorch [github]
- Intel Extension for TensorFlow [github]
Now Available: 6 New AI Reference Kits
February 10, 20232 |AI Reference Kits
Next 6 AI Reference Kits Bolster AI Acceleration Across Multiple Industries and Architectures… FREE
Since the fall of 2022, Intel has collaborated with Accenture to introduce AI reference kits covering industries such as energy & utilities, financial services, health & life sciences, retail, semiconductor, and telecommunications.
Today, 6 more join the list (almost 30 total!). All are powered by oneAPI and can be applied freely to an increasing complement of AI workloads.
Learn more and download the AI Ref Kits
The Rundown
Below is an overview of the next AI Ref Kits available, which are powered by oneAPI including optimized frameworks and oneAPI libraries, tools, and other components to maximize AI performance on Intel® hardware:
- Traffic Camera Object Detection for developing a computer vision model to predict the risk of vehicle accidents by analyzing images from traffic cameras in real time.
- Computational Fluid Dynamics for developing a deep learning model to numerically solve equations calculating fluid-flow profiles.
- AI Structured Data Generation for developing a model to synthetically generate structured data, including numeric, categorical, and time series.
- Structural Damage Assessment for developing a computer vision model using satellite images to assess the severity of damage caused by natural disasters.
- Vertical Search Engine for developing a natural language processing (NLP) model for semantic search through documents.
- Data Streaming Anomaly Detection for developing a deep learning model to help detect anomalies in sensor data that monitors equipment conditions.
Learn More
- Intel Releases AI Reference Kits [press release]
- Intel Releases Open Source Reference Kits [blog]
Just Launched: New Intel® CPUs and GPUs
January 10, 2023 | Intel® oneAPI and AI Tools
![]()
![]()
![]()
![]()
Today, Intel marked one of the most important product launches in company history with the unveiling of its highly anticipated CPU and GPU architectures:
- 4th Gen Intel® Xeon® Scalable processors (code-named Sapphire Rapids)
- Intel® Xeon® CPU Max Series (code-named Sapphire Rapids HBM)
- Intel® Data Center GPU Max Series (code-named Ponte Vecchio)
These feature-rich product families bring scalable, balanced architectures that integrate CPU and GPU with the oneAPI open software ecosystem, delivering a leap in data center performance, efficiency, security, and new capabilities for AI, the cloud, the network, and exascale.
Scale a Single Code Base across Even More Architectures
When coupled with the 2023 Intel® oneAPI and AI tools, developers can create single source, portable code that fully activates the advanced capabilities and built-in acceleration features of the new hardware.
- 4th Gen Intel Xeon & Intel Max Series (CPU) processors provide a range of features for managing power and performance at high efficiency, including these instruction sets and built-in accelerators: Intel® Advanced Matrix Extensions, Intel® QuickAssist Technology, Intel® Data Streaming Accelerator, and Intel® In-Memory Analytics Accelerator.1
- Activate Intel® AMX support for int8 and bfloat16 data types using oneAPI performance libraries such as oneDNN, oneDAL, and oneCCL.
- Drive orders of magnitude for training and inference into TensorFlow and PyTorch AI frameworks which are powered by oneAPI and already optimized to enable Intel AMX.
- Deliver fast HPC applications that scale with techniques in vectorization, multithreading, multi-node parallelization, and memory optimization using the Intel® oneAPI Base Toolkit and Intel® oneAPI HPC Toolkit.
- Deliver high-fidelity applications for scientific research, cosmology, motion pictures, and more that leverage all of the system memory space for even the largest data sets using the Intel® oneAPI Rendering Toolkit.
- Explore workload types, oneAPI tools, and other resources for these new CPUs >
- Intel Data Center GPU Max Series is designed for breakthrough performance in data-intensive computing models used in AI and HPC such as physics, financial, services, and life sciences. This is Intel’s highest performing, highest density discrete GPU—it has more than 100 billion transistors and up to 128 Xe cores.
- Activate the hardware’s innovative features—Intel® Xe Matrix Extensions, vector engine, Intel® Xe Link, data type flexibility, and more—and realize maximum performance using oneAPI and AI Tools.
- Migrate CUDA* code to SYCL* for easy portability across multiple architectures—including the new GPU as well as those from other vendors—with code migration tools to simplify the process.
- Explore workload types, oneAPI tools, and other resources for the new GPU >
“The launch of 4th Gen Xeon Scalable processors and the Max Series product family is a pivotal moment in fueling Intel’s turnaround, reigniting our path to leadership in the data center, and growing our footprint in new arenas.” – Sandra Rivera, Intel Executive VP and GM of Datacenter and AI Group
Learn More
- Get the details
- New Intel oneAPI 2023 Tools Maximize Value of Upcoming Intel Hardware
- Compare CPUs, GPUs, and FPGAs for oneAPI Compute Workloads
- [Programming Guide] Port Intel® C++ Compiler Classic to Intel® oneAPI DPC++/C++ Compiler
- [On-Demand Webinar] Tune Applications on CPUs & GPUs with an LLVM*-Based Compiler from Intel
1The Intel Max Series processor (CPU) also offers 64 gigabytes of high bandwidth memory (HBM2e), significantly increasing data throughput for HPC and AI workloads.
Intel’s 2023 oneAPI & AI Tools Now Available in the Intel® Developer Cloud
December 16, 2022 | Intel® oneAPI and AI Tools, Intel® Developer Cloud, oneAPI initiative
Optimized, Standards-based, Multiarchitecture Performance
Just announced today, Intel® oneAPI and AI 2023 tools are now available in the Intel Developer Cloud and have started rolling out through regular distribution channels.
This release continues to empower developers with multiarchitecture performance and productivity, delivering optimized support for Intel’s upcoming portfolio of CPU and GPU architectures and advanced capabilities:
- 4th Gen Intel® Xeon® Scalable Processors and the Intel® Xeon® Processor Max Series (formerly codenamed Sapphire Rapids) with Intel® Advanced Matrix Extensions (Intel® AMX), Quick assist Technology (QAT), Intel® AVX-512, bfloat16, and more
- Intel® Data Center GPUs, including Flex Series with hardware AV1 encode and Max Series (formerly codenamed Ponte Vecchio) with datatype flexibility and Intel® Xe Link, Intel® Xe Matrix Extensions (Intel® XMX), vector engine, and other features
- Existing Intel® CPUs, GPUs, and FPGAs

The Highlights: What’s New in the 2023 oneAPI and AI Tools
Compilers & SYCL Support
- Intel® oneAPI DPC++/C++ Compiler improves CPU and GPU offload performance and broadens SYCL language support for improved code portability and productivity
- Intel® oneAPI DPC++ Library (oneDPL) expands support of the C++ standard library in SYCL kernels with additional heap and sorting algorithms and adds the ability to use OpenMP for thread-level parallelism.
- Intel® DPC++ Compatibility Tool (based on the open source SYCLomatic project) improves migration of CUDA library APIs, including those for runtime and drivers, cuBLAS, and cuDNN.
- Intel® Fortran Compiler provides full Fortran language standards support through Fortran 2018; implements coarrays, eliminating the need for external APIs such as MPI or OpenMP; expands OpenMP 5.0 and 5.1 offloading features; adds DO CONCURRENT GPU offload; and improves optimizations for source-level debugging.
Performance Libraries
- Intel® oneAPI Math Kernel Library increases CUDA library function API compatibility coverage for BLAS and FFT; for Ponte Vecchio, leverages Intel® XMX to optimize matrix multiply computations for TF32, FP16, BF16, and INT8 data types.
- Intel® oneAPI Threading Building Blocks improves support and use of the latest C++ standard for parallel_sort, offers an improved synchronization mechanism to reduce contention when multiple task_arena calls are used concurrently, and adds support for Microsoft Visual Studio 2022 and Windows Server 2022.
- Intel® oneAPI Video Processing Library supports the industry’s first hardware AV1 codec in the Intel Data Center GPU Flex Series and Intel® Arc™ processors; expands OS support for RHEL9, CentOS Stream 9, SLES15Sp4, and Rocky 9 Linux; and adds parallel encoding feature to sample_multi_transcode.
Analysis & Debug
- Intel® VTune™ Profiler enables ability to identify MPI imbalance issues via its Application Performance Snapshot feature.
- Intel® Advisor adds automated roofline analysis for Intel Data Center GPU MAX Series to identify and prioritize memory, cache, or compute bottlenecks and understand their causes, and delivers actionable recommendations for optimizing data-transfer reuse costs of CPU-to-GPU offloading.
AI and Analytics
- Intel® AI Analytics Toolkit can now be run natively on Windows with full parity to Linux except for distributed training (GPU support is coming in Q1 2023).
- Intel® oneAPI Deep Neural Network Library further supports delivery of superior deep learning performance by enabling advanced features in 4th Gen Intel Xeon Scalable Processors including Intel AMX, AVX-512, VNNI, and bfloat16.
- Intel® Distribution of Modin integrates with new heterogeneous data kernels (HDK) solution in the back end, enabling AI solution scale from low-compute resources to large- or distributed-computed resources.
Rendering & Visual Computing
- Intel® oneAPI Rendering Toolkit includes the Intel® Implicit SPMD Program Compiler runtime library for fast SIMD performance on CPUs.
- Intel® Open Volume Kernel Library increases memory-layout efficiency for VDB volumes and adds an AVX-512 8-wide CPU device mode for increased workload performance.
- Intel® OSPRay and Intel® OSPRay Studio add features for multi-segment deformation motion blur for mesh geometry, primitive, and objects; face-varying attributes for mesh and subdivision geometry; new light capabilities such as photometric light types; and instance ID buffers to create segmentation images for AI training.
Learn More
- See the benchmarks >
- Get the full details >
- Get a free Developer Cloud account >
- Compare Benefits of CPUs, GPUs, and FPGAs for oneAPI Workloads >
- New to SYCL? Get started here >
- Bookmark the oneAPI Training Portal – Learn the way you want to with learning paths, tools, on-demand training, and opportunities to share and showcase your work.
Codeplay Announces oneAPI Plugins for Nvidia and AMD GPUs
December 16, 2022 | Codeplay Software
![]() Multiarchitecture, multivendor programming just got easier.
Multiarchitecture, multivendor programming just got easier.
Today, Codeplay Software1 announced expanding oneAPI support for Nvidia and AMD GPUs via compiler plugins, enabling developers to target a broader set of platforms and architectures.
The Details:
- These plugins seamlessly work with the 2023 Intel® oneAPI DPC++/C++ Compiler2 and many popular libraries.
- Specific to the oneAPI Nvidia GPU plugin, Codeplay is providing complementary, enterprise-ready Priority Support, enabling developers to get accelerated responses directly from Codeplay engineers and more.
- Codeplay is additionally providing a beta release of the oneAPI AMD GPU plugin that can be used with the Intel® oneAPI DPC++/C++ Compiler.
Get the full story here >
Download the Nvidia GPU plugin >
Download the AMD GPU plugin >
More from Codeplay:
- Expanding Our Open Standards with Intel
- Building an Open Standard Heterogeneous Software Platform on oneAPI
- SYCL Training Program
- oneAPI Solutions & Contributions
1Codeplay is an Intel company
2The oneAPI for Nvidia and AMD plugins can be used with the Intel® oneAPI DPC++/C++ Compiler 2023.0 or later version (the compiler is a component of the Intel® oneAPI Base Toolkit).
oneAPI Spec 1.2 Release PLUS New Members Added to Steering Committee
November 14, 2022 | oneAPI initiative
The oneAPI Specification 1.2 is comprised of a major new release of the oneDNN specification which includes the brand new oneDNN Graph API, bringing enhanced performance by enabling a larger scope of deep neural network (DNN) compute graph functionality.
Additional features include:
- Updates and extensions to DPC++ (oneAPI’s open source SYCL implementation)
- Enhancements to oneMKL, with new routines for the BLAS libraries
- oneVPL’s addition of a new API for processing camera RAW data and more
- Level Zero’s addition of a fabric topoloty discovery API and sRGB support for image copy
oneAPI Community Forum Expansion
Led by Rod Burns, VP of Ecosystem at Codeplay Software, the forum has added the following new members to its steering committee:
- Kevin Harms from Argonne National Labs – Performance Engineering Team Lead, MS in Computer Science
- Penporn Koanantakool from Google – Sr. Software Engineer, Ph.D in Computer Science
- Robert Cohn from Intel – Sr. Principal Engineer, Ph.D in Computer Science
Intel @ Supercomputing 2022 – Open, Accelerated Computing for HPC and AI
November 09, 2022 | Intel® oneAPI and AI Toolkits, oneAPI initiative
A lot of developer goodness was announced today by Jeff McVeigh, Intel VP and GM of its Super Computing group, Here are the highlights.
oneAPI and AI Tools 2023 Release
Available in December, Intel’s oneAPI and AI 2023 tools will provide optimized support for powerful new architectures, including the 4th Gen Intel® Xeon® Scalable Processor, Intel® Xeon® Processor Max Series (formerly codenamed Sapphire Rapids HBM), and Intel® Data Center GPU Max Series (formerly codenamed Ponte Vecchio).
These standards-based tools continue to help developers deliver multiarchitecture performance and productivity. New HPC and AI features include:
- HPC and General Compute – Select tools support OpenMP 5.1, Intel® oneAPI DPC++/C++ Compiler provides improved SYCL language support, and Intel® Fortran Compiler fully implements F2003, F2008 and F2018 standards across Intel® CPUs and GPUs.
- AI – Optimizations for TensorFlow and PyTorch accelerate performance on current and upcoming Intel CPUs and GPUs. Extended quantization and distillation capabilities in the Intel® Neural Compressor deliver faster AI inference. These features are bundled in the Intel® AI Analytics Toolkit powered by oneAPI.
- Code Portability – Enhanced CUDA-to-SYCL code migration functions simplify creating single-source code for multiarchitecture systems.
Other enhancements for this release were previewed at Intel® Innovation on Oct. 28.
7 New AI Reference Kits Released
To accelerate industry-driven solutions for AI, Intel recently released 7 new AI reference kits to address key business issues. The kits are powered by oneAPI and include optimized frameworks and oneAPI libraries, tools, and other components to maximize AI performance on Intel® hardware. The new kits target:
- Health & Life Sciences - speech-to-text AI
- Retail – personalize experiences with customer segmentation, automate purchase prediction, demand forecasting, order-to-delivery forecasting
- Financial Services - loan default risk prediction
- Cross-industry - network intrusion detection
These kits join 9 others for a total of 16. Get them now via Intel or on GitHub.
New oneAPI Center of Excellence Focuses on Earthquake Research
The Southern California Earthquake Center with the San Diego Supercomputer Center at UC San Diego is hosting a new oneAPI Center of Excellence. The center’s focus addresses the challenges of numerically simulating the dynamics of fault rupture and seismic ground motion in realistic 3D models. It will optimize Anelastic Wave Propagation – Olsen, Day, Cui (AWP-ODC) software, an open source simulation code, using oneAPI to create portable, high-performance, multiarchitecture code for advanced HPC systems.
The Anelastic Wave Propagation code is used extensively by the SCEC community, the National Science Foundation consortium, and scientists and researchers in real-world seismic hazard simulations and research domains. It enables computational productions from standard “forward” simulations (computing three-component seismograms, i.e., records of earthquake phenomena) to multiple-source “reciprocal” simulations (calculating seismic hazard estimates for sites of interest). The computational outcomes allow for ground motion predictions that help decision-makers reduce seismic risk by improving building codes and increasing community resilience to earthquake hazards.
This oneAPI Center of Excellence joins 28 others around the globe working to accelerate oneAPI through research, code optimizations and implementations, and training programs.
Intel® oneAPI 2022.3 Tools Available
October 10, 2022 | Intel® oneAPI and AI Toolkits, oneAPI initiative
![]() Enabling an Open, Multiarchitecture World
Enabling an Open, Multiarchitecture World
The newest update of Intel® oneAPI Toolkits and standalone tools is now available for direct download and/or use in the Intel® DevCloud for oneAPI. More than 30 tools are included in this release, each optimized to deliver improved performance and expanded capabilities for data-centric workloads.
Intel oneAPI Toolkits are purpose-built to optimize and accelerate cross-architecture and heterogeneous computing, delivering to developers open choice without sacrificing performance or functionality.
The toolkits provide compilers, languages, libraries, and analysis and debug tools that implement industry standards including SYCL*, C++, C, Python, Fortran, MPI, and OpenMP* as well as optimized versions of popular AI frameworks and Python libraries.
2022.3 Highlights:
Compilers
- Intel® oneAPI DPC++/C++ Compiler adds more SYCL 2020 features to improve programming productivity on various hardware accelerators including GPUs and FPGAs and enhances OpenMP 5.x compliance.
- Intel® Fortran Compiler adds Fortran 2008 and 2018 coarrays, DLLImport/DLLExport, DO CONCURRENT offload support, and -int and additional -check compiler options.
CUDA*-to-SYCL Porting
- Intel® DPC++ Compatibility Tool supports more complete CUDA-to-SYCL code migration by adding support for CUDA 11.7 header files and CUDA runtimes and driver APIs including cuDNN, NCCL, Thrust, cuBLAS, and cuFFT.
- The SYCLomatic Project expands Intel’s support of open computing with an open source version of the Compatibility Tool, which enables community collaboration to advance adoption of the SYCL standard.
Performance Libraries
- Intel® oneAPI Math Kernel Library adds BLAS GPU device-timing support to ensure faster and easier detecting of exceptions and quicker recovery; improves portability and compatibility by extending OpenMP cluster offload capability to support the OpenMP 5.1 spec for LAPACK.
- Intel® oneAPI DPC++ Library expands support of the C++ standard library in SYCL kernels with nine additional heap and sorting algorithms to simplify the coding of common functions.
- Intel® oneAPI Video Processing Library includes the ability to provide extensive data about what is encoded, thereby opening up opportunities for quality improvement and algorithm innovation.
Analysis & Debug Tools
- Intel® VTune™ Profiler, Intel® Advisor, and Intel® Inspector include recent versions of 3rd party components including function and security updates.
- Intel® Distribution for GDB* enhances usability and stability for seamless GPU-side debugging.
- Intel® Cluster Checker supports the IBM Spectrum LSF* workload management platform for demanding, distributed HPC environments.
AI and Analytics
- Intel® Extension for PyTorch* is updated to 1.12.100, includes automatic INT8 quantization, and adds operation and graph enhancements to improve performance across a broad set of workloads.
- Intel® Optimization for TensorFlow* is updated to TensorFlow 2.9.1, includes performance improvements for bfloat16 models, and removes compiler requirement to enable oneDNN optimizations on Linux*-based Cascade Lake and newer CPUs.
- Intel® Neural Compressor improves productivity with a lighter binary size, a new quantization accuracy feature and experimental auto-coding support, plus adds support for TensorFlow quantization API, QDQ quantization for ITEX, mixed-precision enhancement, DyNAS, training for block-wise structure sparsity, and op-type wise tuning strategy.
Rendering & Ray Tracing
- Intel® Open Volume Kernel Library improves performance and memory efficiencies and adds support for VDB volumes (packed/contiguous data layouts for temporally constant volumes) and Intel® AVX-512 8-wide CPU device mode.
- Intel® OSPRay supports primitive, object, and instance ID buffers as framebuffer channels, and face-varying attributes for mesh and subdivision geometry.
- Intel® Embree supports the Intel oneAPI DPC++/C++ Compiler.
Bookmark the oneAPI Training Portal – Learn the way you want to with learning paths, tools, on-demand training, and opportunities to share and showcase your work.
oneAPI Initiative Expands to a Community Forum for Open Accelerated Computing
September 28, 2022 | oneAPI Initiative & Specification
The future of oneAPI is shifting to a community forum to address the evolving needs of developers, software vendors, national labs, researchers, and silicon vendors.
Why? To build on the progress made on oneAPI adoption and implementations across multiple architectures and vendors.
Codeplay will lead in establishing the forum to grow and coordinate the oneAPI developer community—its history driving open standards and cross-platform experience with SYCL* development and oneAPI implementationss uniquely position it to facilitate these next steps.
Benefits
The forum will lead to greater community participation and guide the continuing evolution of oneAPI to enable more cross-architecture, multivendor implementations, and rapid adoptions.
Codeplay, in concert with the community, will provide additional details on the transition in the next quarter.
Get the details
- Join the oneAPI community and participate in collaborations
- Read blogs for more details: oneAPI Expands to a Community forum by Sanjiv Shah (Intel VP) | Building an Open Standard, Open-Source Heterogeneous Software Platform by Rod Burns (Codeplay Software VP)
Sneak Peek: 2023 Intel® oneAPI Tools
September 28, 2022 | Intel® oneAPI Toolkits
![]() New Enhancements Coming in December
New Enhancements Coming in December
Winter is coming. Which means that Intel® oneAPI tools (toolkits and standalone tools) are on the precipice of revving to improved and optimized versions that are purpose-built to help developers continually deliver applications and solutions that work across multiple architectures—CPU, GPU, FPGA, and more.
The 2023 release includes enhancements to its standards-based developer products that are optimized for the latest and upcoming architectures (solely or in combination) such as:
- 4th Gen Intel® Xeon® Scalable Processor
- Intel® Data Center GPU codenamed Ponte Vecchio
- Intel® Data Center GPU Flex Series
- Intel® Arc™ Graphics
- Intel® Agilex™ FPGAs
New top features include:
- HPC and General Compute – Enhanced CUDA-to-SYCL code migration functions simplify creating performant single source code for multiarchitecture systems. The Intel® oneAPI DPC++/C++ Compiler provides improved SYCL language support and the Intel® Fortran Compiler fully implements F2003, F2008 and F2018 standards across Intel CPUs and GPUs.
- Artificial Intelligence – TensorFlow* and PyTorch* are optimized for the 4th gen Xeon Scalable processor and Ponte Vecchio. Extended quantization and distillation capabilities in the Intel® Neural Compressor deliver faster AI inference. These features are bundled in the Intel® AI Analytics Toolkit powered by oneAPI.
The tools begin shipping in December.
Announcing 6 New oneAPI Centers of Excellence
September 28, 2022 | Academic Centers of Excellence
Six new oneAPI Centers of Excellence recently joined the oneAPI community. They will focus on accelerating oneAPI development on multiarchitecture systems by optimizing key software codes, creating new implementations, porting strategic applications to oneAPI, and developing and broadly sharing new curriculum to enable and expand oneAPI adoption.
The six new oneAPI Centers are:
- Science and Technology Facilities Council will accelerate exascale software development on multiarchitecture systems using the SYCL* standard and oneAPI with specific focus on optimizing two prominent open source HPC software codes: a C++ coupling library called Multiscale Universal Interface (MUI) and a high-fidelity Computational Fluid Dynamics code called Xcompact3d. Both are integral within the UK’s ExCALIBUR exascale programme and part of its landscape for developing future exascale computing capabilities, providing accelerated computing platforms that can handle upwards of a trillion of calculations per second.
- School of Software and Microelectronics of Peking University is expanding teaching and practical usage of oneAPI programming, including developing and teaching classes and broadly sharing the new local language curriculum to enable and expand oneAPI adoption at universities in the People’s Republic of China.
- Technion Israel Institute of Technology is facilitating studies in contemporary scientific computing on CPUs, GPUs, and other accelerators using oneAPI and Intel® Developer Cloud. Advanced courses using oneAPI and OpenMP* will expand to other universities. Undergraduate projects will also port select open source HPC and AI applications via oneAPI to OpenMP/SYCL and optimize their performance. Read more: English | Hebrew
- University of California San Diego will focus on enabling high-performance molecular dynamics simulations in Amber via oneAPI—CPUs and accelerators—at its Supercomputer Center.
- University of Utah in collaboration with the Lawrence Livermore National Laboratory is focused on developing portable, scalable, and performant data compression techniques by accelerating ZFP compression software using oneAPI on multiple architectures to advance exascale computing.
- Zuse Institute Berlin is focused on using oneAPI for energy-efficient HPC computing by delivering portable implementations on GPUs and FPGAs.
To date, 28 oneAPI Centers of Excellence are driving oneAPI open accelerated compute adoption around the world.
Learn more: oneAPI Centers of Excellence
Now Available: 3 New AI Reference Kits
September 28, 2022 | AI Reference Kits
Solve important business problems.
Building on a set of AI SW Reference Kits released in July (in collaboration with Accenture), three new AI application reference kits powered by oneAPI are now available for healthcare to help clinicians with disease prediction, medical imaging diagnostics, and document automation. The kits can be downloaded from Intel or GitHub.
A continuing drumbeat of new AI reference kit releases will continue through 2023.
Joint Solution with Red Hat Accelerates AI, New Data Science Developer Program
September 28, 2022
New Enhancements Coming in December
![]() Intel and Red Hat introduced a new joint solution that combines Intel’s AI hardware and software portfolio with Red Hat OpenShift Data Science (RHODS), an AI platform that enables data scientists and developers to work together to create, test, and build intelligent applications.
Intel and Red Hat introduced a new joint solution that combines Intel’s AI hardware and software portfolio with Red Hat OpenShift Data Science (RHODS), an AI platform that enables data scientists and developers to work together to create, test, and build intelligent applications.
This solution enables developers to train and deploy their models using the Intel® AI Analytics Toolkit and OpenVINO™ tools, which are powered by oneAPI.
Red Hat is also working to make the Habana Gaudi* training accelerator available on its service to deliver cost-efficient, high-performance, deep-learning model training and deployment. Additionally, a joint Intel and Red Hat AI developer program will enable developers to learn, test, and deploy AI software directly from both the RHODS sandbox and the Intel® Developer Cloud.
Learn more: Developer Resources from Intel & Red Hat | Boost OpenShift Data Science with Intel® AI Analytics Toolkit
For a Limited Time: Get Beta Access to New Intel® Technologies
September 27, 2022 | Intel® Developer Cloud
![]() New technologies are a click away in the expanded Intel® Developer Cloud.
New technologies are a click away in the expanded Intel® Developer Cloud.
As noted by Intel CEO Pat Gelsinger during his keynote at Intel® Innovation, a limited beta trial opportunity is now open to for the newly expanded Intel® Developer Cloud.
Starting right now, approved developers and customers can get early access to Intel technologies—from a few months to a full year ahead of product availability—and try out, test, and evaluate them on Intel’s enhanced, cloud-based service platform.
The beta trial includes new and upcoming Intel compute and accelerator platforms such as:
- 4th Gen Intel® Xeon® Scalable Processors (Sapphire Rapids)
- Intel® Xeon 4th Gen® processor with high bandwidth memory (HBM)
- Intel® Data Center GPU codenamed Ponte Vecchio
- Intel® Data Center GPU Flex Series
- Habana® Gaudi®2 Deep Learning accelerators
Registration and prequalification is required.
Visit cloud.intel.com to get started.
Intel Among Official TensorFlow Build Collaborators
September 21, 2022 | TensorFlow install with pip
 Intel has officially partnered with Google to take ownership of developing and releasing TensorFlow Windows Native CPU builds, starting with TensorFlow 2.10. This close collaboration with Google underscores Intel’s commitment to deliver optimal experience for TensorFlow developers on Windows platforms.
Intel has officially partnered with Google to take ownership of developing and releasing TensorFlow Windows Native CPU builds, starting with TensorFlow 2.10. This close collaboration with Google underscores Intel’s commitment to deliver optimal experience for TensorFlow developers on Windows platforms.
Tencent Achieves Up to 85% Performance Boost using oneAPI Tools
September 12, 2022 | Intel® oneAPI DPC++/C++ Compiler, Intel® VTune™ Profiler
Tencent’s results with optimizing MySQL demonstrate the importance both of using up-to-date [Intel® oneAPI] developer tools like the Intel oneAPI DPC++/C++ Compiler and the latest optimization techniques using Intel VTune Profiler. The significant improvements in performance yield either faster time-to-results or more results for business-critical applications.
Tencent significantly enhanced the performance of its database hosting service, TencentDB for MySQL. Based on the open source relational database management system MySQL and built on Intel® Xeon® processors, performance increased by using the advanced Intel® oneAPI DPC++/C++ Compiler and Intel® VTune™ Profiler (part of the Intel® oneAPI Base Toolkit).
Why It Matters
Distributed data storage serves a critical role across industries and use cases, including internet, finance and e-commerce. Solutions like TencentDB for MySQL provide developers with a service for distributed data storage that supports easy setup, operation and expansion of relational databases in the cloud.
From Rendering to HPC, Intel® oneAPI Tools are Optimizing Open Source Solutions
September 8, 2022 | Intel® oneAPI Base Toolkit, Intel® oneAPI HPC Toolkit, Intel® oneAPI Rendering Toolkit
New this week, two popular and powerful applications, Blender 3.3 and Radioss (which now has an open source version: OpenRadioss), are optimized by very different (and very important) oneAPI tools and capabilities that benefit developers.
Check them out:
Blender Cycles Provides Full Support for Intel Discrete GPUs
Starting with Blender 3.3, the Cycles rendering engine now includes oneAPI as a rendering device API with support for Intel® Arc™ A-series discrete graphics and Intel® Data Center GPU Flex Series. The new support is implementing SYCL, by The Khronos Group, an open, standards-based language that provides multivendor CPU and GPU code development. This is a first step in an evolutionary development approach that aims to free Blender creators and users from being locked into single, proprietary architecture and programming.
Cycles is a ray tracing renderer in Blender with complex path-tracing scenes, geometry notes, indirect lighting and dense geometry for final frames. Over the years, Intel’s contributions to Blender include development consulting, integrating advanced ray tracing capabilities, and training. Intel® Embree, the academy award-winning 3D ray tracing kernel library, was integrated into Blender several years ago, delivering high-fidelity photorealism and supporting many films and projects. In 2019, Intel® Open Image Denoise was added, helping artists and studios deliver final frame image quality in less time.
Altair Unveils OpenRadioss
Altair taking OpenRadioss into the open source community enables developers who want to solve critical problems in structural analysis like crash simulation access to the benefits of open source development. Intel’s commitment to open source development is reflected in collaboration with Altair using open oneAPI compilers, libraries, and developer tools that help them productively maximize value from their high-performance hardware.
Altair has moved Radioss—a leading analysis solution to improve the crashworthiness, safety, and manufacturability of complex designs—to open source as OpenRadioss. Altair engineers used several tools in the Intel® oneAPI Base and HPC Toolkits to optimize the software.
Learn more > Watch the video >
New Intel® Data Center GPU Flex Series for the Intelligent Visual Cloud Uses an Open Software Stack
Aug. 24, 2022 | oneVPL | Intel® VTune™ Profiler
Unveiled today, the Intel® Data Center GPU Flex Series is a versatile and seamless hardware with an open software solution stack that brings much-needed flexibility and performance to intelligent visual cloud workloads.
It delivers:
- 5x media transcode throughput performance and 2x decode throughput performance at half the power of competitive solutions1
- More than 30% bandwidth improvement for significant total cost of ownership (TCO) savings
- Broad support for popular media tools, APIs, frameworks, and the latest codecs
The Intel Flex Series GPU is designed to flexibly handle a wide range of workloads—media delivery, cloud gaming, AI, metaverse, more—without compromising performance or quality, while lowering and optimizing TCO. The GPU frees users from the constraints of siloed and proprietary environments and reduces the need for data centers to use separate, discrete solutions.

Developers can access a comprehensive software stack that combines open source components and tools to effectively realize the Flex Series GPU capabilities for visual cloud workloads. Intel’s oneAPI tools empower developers to deliver accelerated applications and services, including oneVPL, Intel® VTune™ Profiler, and many more.
Watch for more details on easy downloadable software packages coming soon.
Learn More: Intel News Byte | Intel Flex Series GPU
3D Artist’s Visuals Come to Life through Intel Hardware & Advanced Ray Tracing
August 16, 2022 | Intel® Open VKL, Intel® oneAPI Rendering Toolkit
Intel® Advanced Ray Tracing + Intel’s mobile HX processors deliver high performance for professional workflows and amazing content creation.
Intel recently released the Intel® Open VKL plugin for RenderMan*. It works with Pixar Animation’s Renderman—one of the world’s most versatile renderers for VFX and animation—and utilizes Intel® Open Volume Kernel Library to provide significant performance improvements for final-frame volumetric rendering.
The powerful combo of Renderman, Intel Open VKL, and 12th Gen Intel® Core™ HX processors helps artists like Fabio Sciedlarczyk render compute-intensive volumetric content more quickly, including fire, water, air, clouds, and smoke. That performance allows him more time to craft a visually stunning story. In this video, see how Sciedlarczyk used these tools to build amazing photoreal visuals, producing them on-the-go without sacrificing performance while dramatically reducing compile times on his mobile workstation.
These days, with the tools I have available, computer graphics is becoming a medium of almost no restrictions. And Intel is continually pushing the boundaries of what’s possible.
The open source plugin is available free to the public on GitHub and aligns with Intel’s open software strategy to foster innovation and broad adoption by content creators and developers across the software ecosystem. Intel Open VKL is part of the Intel® oneAPI Rendering Toolkit.
More Resources
Intel and Aible Team Up to Fast-Track AI
August 9, 2022 | Aible, Intel® AI Analytics Toolkit
Intel® Xeon® Scalable processors, along with software optimizations, enable business results within 30 days.
Intel’s collaboration with Aible, a cloud-based AI/ML platform solution provider, enables customers to deliver datacenter-based AI applications and initiatives faster and with better TCO without increasing complexity.
When paired with AI-accelerated Intel® Xeon® Scalable processors plus AI-optimized tools: oneAPI Deep Neural Network Library (oneDNN) + others from Intel® AI Analytics Toolkit, Aible’s technology provides a serverless-first approach that trains machine learning modules faster than other server-oriented solutions.
Deploy Stunning Hi-Fi Graphics with Intel® Advanced Ray Tracing
August 8, 2022 | [NEW!] Intel® Arc™ Pro A-series graphics, Intel® Open VKL plugin for RenderMan*, Intel® Open Path Guiding Library, SIGGRAPH 2022
Newly Unveiled: Intel® Arc™ Pro GPUs, Intel® Open VKL Plugin for Renderman*, and Open Path Guiding Library
Just in time for SIGGRAPH 2022, Intel introduced new GPU hardware and software technologies that accelerate high-fidelity graphics. These innovations showcase the next step in the company’s mission to provide open, end-to-end, platform-wide solutions for performance scaling across consumer and high-end laptops, workstations, data center/render farm, cloud - to the world’s largest supercomputers.
Highlights
The Intel Arc Pro A-series professional range of GPUs feature built-in ray-tracing hardware, industry-first AV1 hardware encoding acceleration, and machine learning capabilities. Learn more >
New Intel® Advanced Ray Tracing technologies enable sophisticated ray tracing, visual compute, high-fidelity, and visualization capabilities.
- Intel® Open VKL plugin for Renderman* provides significant improvements for final-frame volumetric rendering.
- Intel® Open Path Guiding Library, the industry’s first open-source library, enables users to easily integrate state-of-the-art path-guiding methods into their renderers.
Cross-industry collaborations with global leaders in standards-based solutions are continuously advancing graphics innovations, with the latest including:
- DreamWorks Animation announced plans to release its MCRT renderer, MoonRay*, as open source software later this year. The renderer’s photoreal ray-tracing performance is supported by two open source tools in the Intel® oneAPI Rendering Toolkit (Render Kit): Intel® Embree ray tracing kernel library for advanced rendering features, and Intel® Implicit SPMD Program Compiler (Intel® ISPC) for vector instruction parallelism.
- Blender* 3.3 is available in beta where oneAPI programming delivers one codebase support on Linux* and Windows* across Intel Arc GPUs and upcoming Intel data center GPUs.
- Intel collaborated with leading Unity asset publisher Procedural Worlds on creating the Intel® Game Dev AI Toolkit with Gaia ML (for Unity). It enables developers to bring machine learning capabilities to their gaming experiences.
- Foundry’s Modo* 16.0 release adds new support to its real-time viewport for upcoming Intel Arc GPUs.
Attending SIGGRAPH 2022?
If so, visit the Intel Booth (#427) to see demos showcasing innovative usages including Topaz and SketchUp running on the just-announced Intel Arc Pro graphics, and SideFX, Blender, and RenderMan optimized by the Render Kit on Intel GPUs and CPUs.
Discover More
Intel Releases Open Source AI Reference Kits to Simplify Development
July 12, 2022 | Intel AI Dev Tools
Intel released the first set of open-source AI reference kits specifically designed to make AI more accessible to organizations in on-prem, cloud, and edge environments.
First introduced at Intel Vision, these kits include AI model code, training data, end-to-end machine learning pipeline instructions, libraries, and Intel® oneAPI components for cross-architecture performance.
The First Kits Available Today
- Utility Asset Health – This predictive analytics model was trained to help utilities deliver higher service reliability.
- Visual Quality Control – Automate VQ control inspections for life sciences, including pharma to help improve the quality of the pills and lower the cost of operations.
- Customer Chatbot for the Enterprise – This conversational AI chatbot model was trained using over 4,000 utterances from the Airline Travel Information Systems dataset to provide 94% predictive accuracy.
- Intelligent Document Indexing – Automate the processing and categorizing of millions of documents via faster routing and lower manual labor costs.
Innovation thrives in an open, democratized environment and Intel’s AI tools and framework optimizations are built on the foundations of an open, standards-based, unified oneAPI programming model. These Project Apollo reference kits, built with components of Intel’s End-to-End AI software portfolio, will enable millions of developers and data scientists to quickly and easily introduce AI into their applications or boost their existing AI/ML implementations. This will help deliver a wide range of intelligent solutions across several use cases and industries.
Intel & Google Cloud Provide Turnkey, Optimized Solution for HPC Workloads
July 6, 2022 | Intel® oneAPI Base Toolkit, Intel® oneAPI HPC Toolkit
Intel and Google are working together to drive high-performance computing forward on Google Cloud with the release of the Cloud HPC Toolkit. This new resource provides access to tools from the Intel® oneAPI Base and HPC Toolkits—including Intel® MPI Library and Intel® oneAPI Math Kernel Library—to optimize performance through Intel® Select Solutions for Simulations & Modeling. These new tools improve compile times and speed of results and offer multi-vendor acceleration in SYCL.
Why It’s Important
In a nutshell, the new Toolkit simplifies adoption of robust high-performance cloud computing by removing the challenges inherent in groking and overcoming unfamiliar development concepts and tools. (These can result in slow deployment for demanding workloads, software incompatibilities, and subpar performance.)
Using Cloud HPC Toolkit with an Intel Select Solutions for Simulations & Modeling blueprint brings the added benefit of automatically spinning up a hardware-software configuration that has been rigorously tested and optimized for real-world performance, eliminating guesswork.
Now Available: Intel® VTune™ Profiler 2022.3
June 7, 2022 | Intel® VTune™ Profiler
Find and optimize performance bottlenecks fast across CPU, GPU, and FPGA systems.
What’s New?
- Supports DirectML API to pinpoint host-side API call inefficiencies and their causes
- Enables developers to identify memory-transfer-related bottlenecks for GPU computing tasks which use USM extension of OpenCL™ API via analyzing CPU-side stacks.
Learn more at software.intel.com/vtune
Intel to Acquire Codeplay Software
June 1, 2022 | oneAPI Specification

Intel is further advancing its support of the oneAPI ecosystem through an agreement to acquire Codeplay Software, a global leader in cross-architecture, open, standards-based developer technologies.
Codeplay is globally recognized for its expertise and leadership in SYCL, the Khronos Group’s open-standard programming model used in oneAPI, and its significant contributions to the industry ranging from open-ecosystem activities like SYCL and OpenCL™ to RISC-V, automotive software safety, and medical imaging.
Codeplay has extensively delivered products supporting diverse hardware platforms globally, embracing the mission of bringing oneAPI to the masses.
Bolstered by the strength of Intel, Codeplay will be able to extend the delivery of SYCL solutions into cross-architecture and multi-vendor products, based on open standards and the open source ecosystems upon which they are built.
Intel at ISC 2022 Focuses on Sustainable, Open HPC-AI
May 31, 2022 | Intel @ ISC 2022
![]()
At International SuperComputing 2022, Jeff McVeigh, VP of Super Compute Group, highlighted Intel’s HPC leadership technologies that are being used to accelerate innovation for a more sustainable and open HPC-AI, including how:
- Intel software and oneAPI extend across the software stack to provide tools, platforms and software IP to help developers produce scalable, better-performing, more efficient code that take advantage of the latest silicon innovations without the burden of refactoring code.
- Two new Intel oneAPI Centers of Excellence join the ecosystem, bringing the total to 22 universities and labs working across the globe to increase oneAPI capabilities and adoption.
Read and watch Jeff’s editorial >
Introducing the New Intel oneAPI Centers of Excellence
- University of Bristol is developing best practices for achieving performance portability at exascale using oneAPI and the Khronos Group* SYCL abstraction layer for cross-platform programming. The goal: ensure scientific codes can achieve high performance on massive heterogeneous supercomputing systems.
- Centre for Development of Advanced Computing (CDAC) is building a base of skilled instructors who deliver oneAPI training to India HPC and AI communities. CDAC will scale training broadly in the country through its infrastructure and teach oneAPI in top universities.
More to Discover
Heidelberg University Drives Heterogeneous Computing with oneMKL Open-source Interfaces
May 25, 2022 | Intel® oneAPI Math Kernel Library, oneAPI Specification
Heidelberg U has recently enabled ROCm support for random number generation and BLAS in Intel® oneAPI Math Kernel Library (oneMKL) interfaces. This is a new and significant community contribution to the oneMKL interfaces project, part of the oneAPI industry initiative that provides SYCL-based APIs for math algorithms focused on CPUs and compute-accelerator architectures.
This work—adding into the project support for rocRAND and rocBLAS—now makes it possible to generate random numbers and perform linear algebra computations using the hipSYCL compiler to achieve near-native performance in cross-platform applications written in hipSYCL. Additionally, it makes oneMKL open-source interfaces the first oneAPI component with upstream support for other SYCL implementations apart from DPC++.
Additional resources
- Learn more of oneAPI specification hipSYCL work at Heidelberg University
- Learn about Heidelberg University’s engineering vision with the oneAPI project
- Understand more about other key contributors to the oneAPI CoE ecosystem
- Learn more about the oneAPI initiative at oneapi.io.
- Start developing with the oneMKL open-source interfaces
oneDNN AI Optimizations Turned Enabled by Default in TensorFlow 2
May 25, 2022 | Intel® oneAPI Deep Neural Network Library
In the latest release of TensorFlow 2.9, performance improvements are delivered by Intel® oneAPI Deep Neural Network Library (oneDNN) enabled by Google as the default backend CPU optimization for x86 packages. This applies to all Linux x86 packages and for CPUs with neural-network-focused hardware features like AVX512_VNNI, AVX512_BF16, and AMX vector and matrix extensions found on 2nd gen Intel® Xeon® Scalable processors and newer CPUs.
These optimizations accelerate key performance-intensive operations such as convolution, matrix multiplication, and batch normalization, with up to 3 times performance improvements compared to versions without oneDNN acceleration.
Why It’s Important
While there is an emphasis today on AI accelerators like GPUs for machine learning and deep learning, CPUs remain a primary player in all stages of the AI workflow—ubiquitous across most personal devices, workstations, and data centers. These default optimizations will help enable millions of developers who already use TensorFlow to achieve productivity gains, faster time to train, and efficient utilization of compute.
Performance gains will benefit applications spanning natural language processing, image and object recognition, autonomous vehicles, fraud detection, medical diagnosis and treatment, and more.
Get the Software
- Download oneDNN standalone or as part of the Intel® oneAPI Base Toolkit.
- Download Intel® Optimization for TensorFlow standalone or as part of the Intel® oneAPI AI Analytics Toolkit.
More Resources
- Discover Intel AI Software Tools
- Read the TensorFlow 2.9 Release blog
Intel Open Sources SYCLomatic Migration Tool to Help Developers Create Heterogeneous Code
May 15, 2022 | Data Parallel C++/SYCL
 Intel recently released an open-source tool to migrate code to SYCL through a project called SYCLomatic; it helps developers more easily port CUDA code to SYCL and C++ to accelerate cross-architecture programming for heterogeneous architectures. This open-source project enables community collaboration to advance adoption of the SYCL standard, a key step in freeing developers from a single-vendor proprietary ecosystem.
Intel recently released an open-source tool to migrate code to SYCL through a project called SYCLomatic; it helps developers more easily port CUDA code to SYCL and C++ to accelerate cross-architecture programming for heterogeneous architectures. This open-source project enables community collaboration to advance adoption of the SYCL standard, a key step in freeing developers from a single-vendor proprietary ecosystem.
How the SYCLomatic Tool Works
SYCLomatic assists developers in porting CUDA code to SYCL, typically migrating 90-95% of CUDA code automatically to SYCL code. To finish the process, developers complete the rest of the coding manually and then custom tune to the desired level of performance.
According to James Reinders, Intel oneAPI evangelist, “Migrating to C++ with SYCL gives code stronger ISO C++ alignment, multivendor support to relieve vendor lock-in, and support for multiarchitecture to provide flexibility in harnessing the full power of new hardware innovations. SYCLomatic offers a valuable tool to automate much of the work, allowing developers to focus more on custom tuning than porting.”
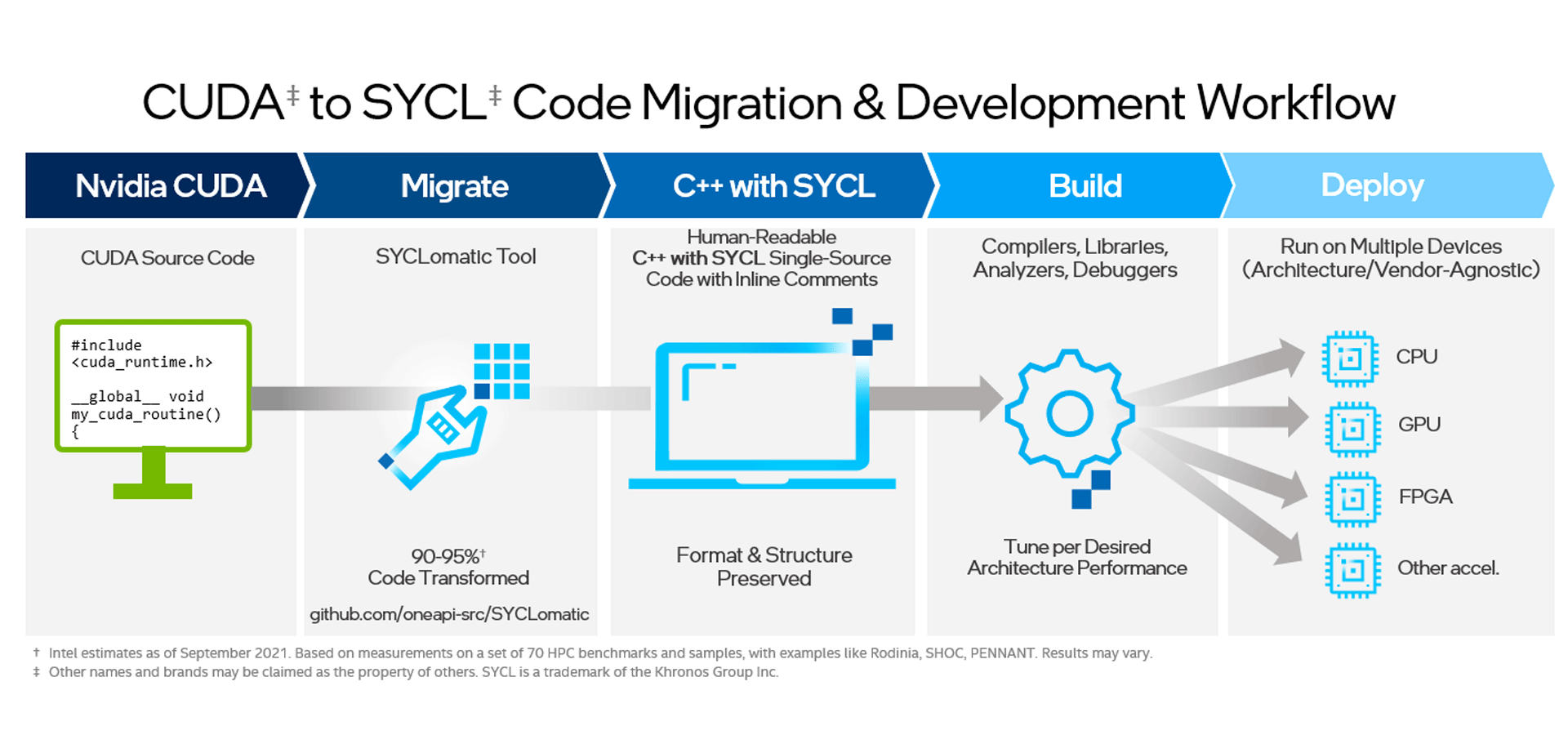
SYCLomatic is a GitHub project. Developers are encouraged to use the tool and provide feedback and contributions to advance the tool’s evolution.
Now Available: Intel® oneAPI Toolkits 2022.2
May 18, 2022 | oneAPI, Intel® oneAPI Toolkits
The latest Intel® oneAPI Tools are now available for direct download and/or use in the Intel® DevCloud. This release includes updates to all Toolkits (including 30+ individual tools)—each optimized to deliver improved performance and expanded capabilities for data-centric workloads.
2022.2 highlights:
Intel® Arc™ (Discrete) GPUs for Media, Gaming, and AI workloads
- Use cross-architecture Intel® oneAPI software tools to create immersive end-user experiences across technologies, platform capabilities, software, and AI-accelerated processing on the GPU combined with the CPU.
- Delivers up to 50x performance improvement over video-software encode with the industry’s first hardware-accelerated AV1 codec, enabled by Intel® oneAPI Video Processing Library (oneVPL). [Benchmark reference below]
- Includes deep learning support via the oneAPI-powered Intel® Distribution of OpenVINO™ toolkit and Intel® oneAPI Deep Neural Networks Library (oneDNN) as well as performance-tuning insights with Intel® VTune™ Profiler.
Compilers
- Intel® oneAPI DPC++/C++ Compiler adds more SYCL* 2020 features to improve developer productivity for programming various hardware accelerators such as GPUs and FPGAs, enhances OpenMP* 5.1 compliance, and improves performance of OpenMP reductions for compute offload.
- Intel® Fortran Compiler, based on modern LLVM technology, adds support for parameterized-derived types, F2018 IEEE Compare, and VAX structures support, and expands support for OpenMP 5.0 with Declare Mapper for scalars support.
High-Performance Libraries
- oneMKL adds MKL_VERBOSE GPU support for the BLAS Domain and CPU support for the transpose domain for improved visibility during debugging.
- oneCCL now supports Intel® Instrumentation and Tracing Technology profiling, opening new insights with tools such as VTune Profiler.
- oneTBB improves support and use of the latest C++ standard for parallel_sort, plus adds fully functional features for task_arena extension, collaborative_all_once, adaptive mutexes, heterogeneous overloads for concurrent_hash_map, and task_scheduler_handle.
- oneVPL supports multiple hardware adapters and expanded development environments, plus MPEG2 decode in a CPU implementation to improve codec coverage for systems that do not have dedicated hardware.
- Intel® MPI Library enables better resource planning and control at an application level with GPU pinning, plus adds multi-rail support to improve application internode communication bandwidth.
Analysis Tools
- Intel® Advisor adds user recommendations and sharing, including optimizing data-transfer reuse costs of CPU-to-GPU offloading, details of GPU Roofline kernels and Offload Modeling, and seeing offloaded parts of the code at source level (including performance metrics) in a GPU Roofline perspective.
- Intel® VTune™ Profiler opens the ability to identify performance inefficiencies related to Intel® VT-d for latest-generation server platforms, supports Intel Arc GPUs, and is available as a Docker container.
AI Workload Acceleration
- Intel® Extension for TensorFlow* adds faster model loading, improvements in efficient element-wise Eigen operations, and support for additional fusions such as matmul biasadd-g.
- Additional functionality and productivity for Intel® Extension for Scikit-learn* and Intel® Distribution of Modin* through new features, algorithms and performance improvements such as Minkowski and Chebyshev distances in kNN and acceleration of the t-SNE algorithm.
- Acceleration for AI deployments with quantization and accuracy controls in the Intel® Neural Compressor, making great use of low-precision inferencing across supported Deep Learning Frameworks.
- Support of new PyTorch model inference and training workloads via Model Zoo for Intel® Architecture, extending support to include Python 3.9, TensorFlow v2.8.0, PyTorch v1.10.0, and IPEX v1.10.0.
Scientific Visualization with Rendering & Ray Tracing
- Intel® Open Volume Kernel Library adds support for IndexToObject affine transform and constant cell data for Structured Volumes.
- Intel® OSPRay and Intel® OSPRay Studio now include support for Multi-segment Deformation Motion Blur for mesh geometry, plus new light features and optimizations.
- Intel® Implicit SPMD Program Compiler Run Time (ISPCRT) library is included in the package.
FPGAs
- Intel® FPGA Add-On for oneAPI Base Toolkit enables users to specify an exact, min, or max latency between read and write access on memories and pipes and provides the ability to implement arithmetic floating point operations involving a constant with either DSPs and ALMs or only ALMs.

GROMACS & oneAPI Aid in Open Source Drug Discovery
May 5, 2022 | oneAPI Spec, Intel® oneAPI Tools

GROMACS, accelerated by SYCL, oneAPI, and multiarchitecture tools, has strong performance on GPUs based on Intel Xe Architecture
The recent GROMACS 2022 release was extended to multi-vendor architectures, including current and upcoming GPUs based on Intel Xe Architecture.
The team, led by Erik Lindahl from Stockholm University & Royal Institute of Technology, ported GROMACS’ CUDA code, which only runs on Nvidia hardware, to SYCL using the Intel® DPC++ Compatibility Tool; the tool typically automates 90%-95% of the code1,2. The result: A single, portable, cross-architecture-ready code base that significantly streamlines development and provides flexibility for deployment in multiarchitecture environments.
The software’s accelerated compute was made possible by using Intel oneAPI cross-architecture tools—oneAPI DPC++/C++ Compiler, oneAPI libraries, and HPC analysis and cluster tools.
With GROMACS 2022’s full support of SYCL and oneAPI, we extended GROMACS to run on new classes of hardware. We’re already running production simulations on current Intel Xe architecture-based GPUs as well as the upcoming Intel Xe architecture-based GPU development platform Ponte Vecchio via the Intel® DevCloud. Performance results at this stage are impressive – a testament to the power of Intel hardware and software working together. Overall, these optimizations enable diversity in hardware, provide high-end performance, and drive competition and innovation so that we can do science faster, and lower costs downstream.
Read the whole story > Watch the video >
About GROMACS
GROMACS is a molecular dynamics package designed for simulations of protein, lipids, and nucleic acids. Its simulations contribute to the identification of crucial pharmaceutical solutions for conditions such as breast cancer, COVID-19, and Type 2 diabetes, and the international distributed-computing initiative Folding@home.
1The team ported GROMACS’ Nvidia CUDA code to Data Parallel C++ (DPC++), which is a SYCL implementation for oneAPI, in order to create new cross-architecture-ready code.
2Intel estimates as of September 2021. Based on measurements on a set of 70 HPC benchmarks and samples, with examples like Rodinia, SHOC, PENNANT. Results may vary.
![]()
Cross-architecture Dev Tools Deliver Incredible End-User Experiences on New GPU Systems
March 31, 2022 | Intel® Software Tools, Intel® Graphics Performance Analyzers, Intel® oneAPI Video Processing Library

If you’re a content creator or game developer, new Intel® Evo™ laptops equipped with Intel Arc A-Series GPUs empower you to create immersive end-user experiences with innovation across technologies, software, and AI-accelerated processing.
And Intel® software tools are a big part of helping developers liberate Intel Arc graphics capabilities and optimize applications for maximum visual performance on the GPU combined with Intel CPUs. Using them, you can:
- Analyze and optimize graphics bottlenecks. Use Intel® Graphics Performance Analyzers to profile graphics and game applications and ramp up profiling abilities with ray tracing, system-level profiling, and Xe Super Sampling (XeSS) capabilities. Capture streams and traces, optimize shaders, and identify the most expensive events with support for multiple APIs (DX, Vulkan, OpenGL, OpenCL, etc.). Download
- Accelerate compute-intensive tasks. Identify the most time-consuming parts of CPU and GPU code. Visualize thread behaviors to quickly find and fix concurrency problems using Intel® VTune™ Profiler. Download
- Speed up media processing and cloud game streaming. Intel® oneAPI Video Processing Library (oneVPL) enables hardware AV1 encode and decode support, and Intel® Deep Link via Hyper Encode APIs, delivering up to 1.4x faster1 single stream transcoding when taking advantage of multiple Intel accelerators in a platform. For content creators already using Handbrake and DaVinci Resolve, oneVPL is integrated into the latest versions. Download
- Integrate AI and machine learning. For game developers, the Intel® Game Dev AI Toolkit delivers a spectrum of AI-powered capabilities, from immersive world creation to real-time game-object-style transfer visualizations. Download
1. Up to 40% higher FPS in video encoding through an internal release of HandBrake on integrated Intel Xe graphics + discrete Intel Arc graphics compared to using Intel Arc graphics alone. Handbrake running on Alchemist pre-production silicon. As of October 2021.
Soda Announces Intel oneAPI Center of Excellence to Support Scikit-learn Performance across Architectures
March 31, 2022 | Intel® Extension for SciKit-learn*
The Social Data research team (Soda) at Inria, France’s national research institute for digital science and technology, is establishing an Intel oneAPI Center of Excellence to focus on developing hardware-optimized performance boosters for scikit-learn, one of the most widely used machine learning libraries.
This scikit-learn extension will deliver more efficient machine learning by using oneAPI numba_dppy or DPC++ components. Additionally, the implementation will be packaged in an independently-managed project possibly maintained by scikit-learn core developers, Intel engineers, and other interested community members.
Heterogenous computing is inevitable. It happens when a host schedules computational tasks to different processors and accelerators like CPUs and GPUs. This partnership will make scikit-learn more performant and energy-efficient on multi-architecture systems.
About Soda
The Social Data research team specializes in computational and statistical research in data science and machine learning—including scikit-learn optimizations—to harness large databases focused on health and social sciences.
Intel Compilers Available in VS Marketplace
March 10, 2022 | Intel® oneAPI DPC++/C++ Compiler
Now there are more ways to download multi-parallelism-supporting compilers. LLVM-based DPC++/C++/C compilers for Windows* can now be downloaded from the Visual Studio Marketplace.
Feature Highlights:
- Include extensions that support productive development of fast, multicore, vectorized, and cluster-based applications.
- Support the latest C/C++ language and OpenMP* standards.
- Support multiple parallelism models and high-performance libraries including oneTBB, oneMKL, oneVPL, and Intel® IPP.
- Can be used to build mixed-language applications with C++, Visual Basic, C#, and more.
Learn more and get the free download >

At Intel’s 2022 Investor Meeting, product updates included next-generation Intel® Xeon® and client CPUs and Ponte Vecchio/Arctic Sound-M GPUs that will accelerate data center, AI, and other segment workloads, along with the software to make this all happen.
Intel’s Software-First strategy was noted in Executive Breakout sessions.
- Greg Lavender, Sr. Vice President, CTO, and GM of Intel Software and Advanced Technology Group, discussed in an editorial and presentation how open, standards-based, cross-architecture programming through oneAPI and Intel® oneAPI Toolkits delivers performance and development productivity across advanced architectures.
- Raja Koduri, Sr. Vice President and GM of Intel Accelerated Computing Systems & Graphics Group, outlined the combined power of hardware and software fronting Intel’s Media and HPC-AI Super Compute Strategies. Highlights:
- Intel® Xeon® processors and an open ecosystem, including oneAPI Video Processing Library, Intel® oneAPI AI Analytics Library, and OpenVINO™ toolkit, deliver high-density, real-time broadcast and premium content to meet global demands where 80% of Internet traffic is video.1
- Upcoming Artic Sound-M GPU will deliver a seamless media supercomputer with leadership transcode performance that addresses quality, latency, and density requirements for desktop and cloud gaming, with an AI analytics engine. It will be the industry’s only open-source media solution stack for streaming, gaming, and analytics, and the industry’s first GPU with AV1 encode that delivers over 30% bandwidth improvement at the same quality.2
- Billions of lines are code are optimized for Xeon, which powers 85% of super computers.3 This sets a strong, seamless ecosystem foundation for the fierce combo of Intel Xeon Sapphire Rapids + Ponte Vecchio GPU, where oneAPI unleashes developers to utilize a range of CPUs and accelerators using a single codebase.
Learn more
- Intel Technology Roadmaps & Milestones
- Intel’s Software Advantage, Decoded
- Software at Intel: Open & Designed with Security in Mind
- Raja Koduri’s Accelerated Computing & Graphics presentation
- oneAPI | Intel® oneAPI Toolkits
1Source Cisco Global 2021 Forecast Highlights
2Source: Mhojhos Research
3Based on TOP500 list over the past decade
Technical University of Darmstadt Establishes Intel oneAPI Center of Excellence
February 14, 2022 | Intel® oneAPI Tools
The Technical University of Darmstadt (TU Darmstadt) Embedded Systems and Applications Group announces establishing an Intel oneAPI Center of Excellence (CoE). The center’s objective is to accelerate data parallel computing and simulation software used in medical and pharmaceutical research powered by oneAPI open cross-architecture programming.
Together with Intel, the university will port an accelerated version of the Autodock application to create a single code base that can be efficiently optimized and tuned for multiple hardware architecture targets.
Additionally, TU Darmstadt is working on a next-gen parallel implementation of Autodock-GPU, which aims to speed up drug-discovery simulations by parallel execution across CPUs, GPUs, and FPGAs.
“The new oneAPI Center of Excellence is an exciting step forward for the multiarchitecture SYCL language and oneAPI,” says Joe Curley, vice president and general manager of Intel Software Products and Ecosystem division. “This collaboration with TU-Darmstadt team provides a path for medical and pharmaceutical researchers to use AutoDOCK-GPU productively on the hardware of their choice.”